Last weekend the paper Growing Cosine Unit: A Novel Oscillatory Activation Function That Can Speedup Training and Reduce Parameters in Convolutional Neural Networks by Noel et alMathew Mithra Noel, Arunkumar L, Advait Trivedi, and Praneet Dutta. 2021. Growing Cosine Unit: A Novel Oscillatory Activation Function That Can Speedup Training and Reduce Parameters in Convolutional Neural Networks. arXiv.2108.12943. surfaced on my social feed. This paper proposes a new oscillatory activation function, called Growing Cosine Unit (GCU), which is supposed to outperform other activation functions, such as SiLUStefan Elfwing, Eiji Uchibe, and Kenji Doya. Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning. arXiv:1702.03118., MishDiganta Misra. 2019. Mish: A self regularized non-monotonic neural activation function. arXiv:1908.08681., and ReLUXavier Glorot, Antoine Bordes, and Yoshua Bengio. 2011. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, PMLR, 315–323.. This immediately drew my attention for two reasons. First, new activation functions are funFor example, last year multiple people fell for this well executed activation function April Fool’s joke., even if most ultimately don’t work. Second, the paper uses Imagenette as one of its datasets to test the proposed activation function on, a dataset I have used in my own research. So I decided to see if I could replicate the results
Partway through my replication efforts, I realized that the GCU paper wasn’t new. It was originally published in 2021 and just received an update this month. Presumably this update was mistaken to be a new paperTo protect the innocent, I won’t mention where I saw the paper, but will state for the record that it wasn’t AK., something I also did not catch when I first skimmed through the paper.
As I was already half-way through my initial replication processes, and it appears no one else has posted about this activation functionAt least from a cursorily search., I decided to finish my replication and create a quick writeup.
# Growing Cosine Unit Overview
The Growing Cosine Unit is defined by equation 1:
which has following graphical representation.
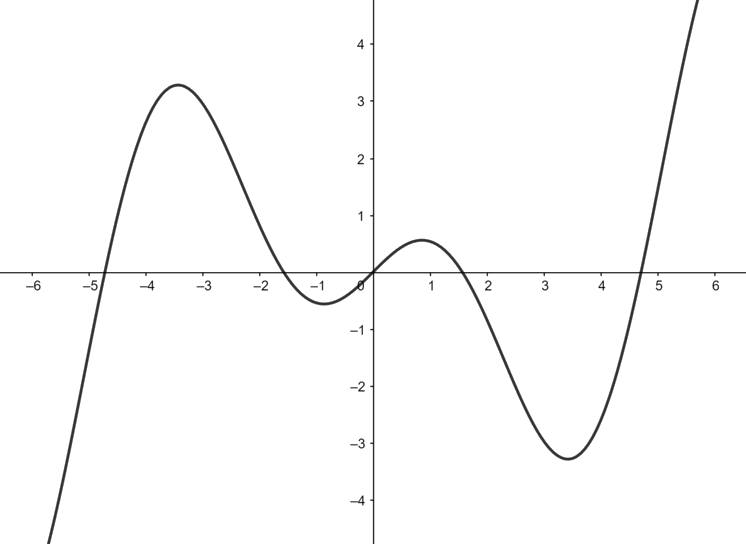
One thing that jumps out immediately is that GCU is the only activation function that I’m aware of where a positive output could result from multiple inputsUsually activation functions are well-defined on the positive x-axis., both positive and negative.
Noel et al state the Growing Cosine Unit provides the following benefits over other activation functions:
- Improves gradient flow and alleviates the vanish gradient problemSimilar to other activation functions with a non-zero negative axis, like Mish and SiLU
- A single GCU neuron can learn the XOR function without feature-engineeringThe example given in the paper looks like it might require more than just one GCU neuron.
- Computationally cheaper than Mish and SiLUWhile GCU itself may be computationally inexpensive, increasing gradient flow slows down the training of neural networks. An effect I overlooked in my blog post on Mish.
- Reduces training time and allows training smaller neural networks
# Paper Results
Noel et al test the GCU activation function on three datasets: CIFAR-10, CIFAR-100, and Imagenette. Furthermore, they don’t use a standard model architecture, but rather a custom miniature VGGKaren Simonyan and Andrew Zisserman. 2014. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv:1409.1556. derived model and VGG-16 for Imagenette. The results from the mini-VGG are unimpressive relative to a CIFAR-10 ResNetKaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). derived modelWhich usually score greater than ninety percent accuracy.. But all the activation functions score in a similar range, so perhaps it’s poorly trained or a sub-optimal model.
Paper mini-VGG CIFAR-10 Results
| Accuracy | Loss | ||||
|---|---|---|---|---|---|
| Conv Act | Linear Act | Mean | StDev. | Mean | StDev. |
| ReLU | ReLU | 74.13% | 0.56% | 0.74 | 0.016 |
| GCU | ReLU | 75.64% | 0.47% | 0.73 | 0.004 |
| SiLU | SiLU | 71.74% | 0.48% | 0.82 | 0.014 |
| SiLU | ReLU | 71.70% | 1.05% | 0.84 | 0.016 |
| Mish | Mish | 74.22% | 0.62% | 0.77 | 0.004 |
| Mish | ReLU | 73.20% | 0.74% | 0.79 | 0.011 |
Five runs of 25 epochs on Noel et al’s custom mini-VGG network.
Table 1 showsNoel et al use Swish, but SiLU is a more accurate citation for the same activation function, so I use it here. that Noel et al do not use GCU by itself in the mini-VGG model, but rather they use a GCU+ReLUI will interchangeably use the terms GCU+ReLU and GCU to mean GCU in convolution layers and ReLU in the linear head of the mini-VGG model for the rest of this post. setup with ReLU in the linear layer feed forward network at the model head and GCU as the activation function for the convolutional blocks.
Fairly or unfairly, I assume a paper in the 2020s which only uses small datasets like CIFAR-10 and 100 will not generalize to larger datasets and modelsEspecially with cheap GPUs from cloud providers like Lambda Labs or free compute for researchers like the TPU Research Cloud are available for training on larger image datasets.. Testing on Imagenette is a small step up from just CIFAR, but I would prefer to see multiple small datasetsMy small-scale research into attention pooling used Imagenette, ImageWoof, and Kaggle’s version of Flowers-102. using more standard models. In this case, the authors use a VGG-16 which scores a 68% Imagenette validation accuracy, which is not competitive with ResNet derived models on the Imagenette leaderboard which, depending on the image size, have scored a 91-93% after 20 epochs since 2020.
But let’s find outPretend you didn’t read the title of this post..
# Replication Setup
Full code to replicate these results is available on GitHub.There are a few immediate issues when attempting to replicate this paper. First, the following paragraph is the extent of the limited details which Noel et al share for their training procedure.
The RMSprop optimizer is used with the categorical cross entropy loss function (softmax classification head). Experiments on CIFAR-10, CIFAR-100 were carried out with an initial learning, decay rate of , respectively. For Imagenette, this was , with no decay. The Xavier Uniform initializer was used to initialize the weights of the kernel layers.
Second, the mini-VGG architecture is described via a diagram in a appendix, also leaving out details. Important replication information, like what batch sizeBy trial and error, I determined that 256 seems to be a decent batch size for an initial learning rate of . But this could be incorrect. was used, dropout, weight decay, etc is not mentioned anywhere.
Fortunately, CIFAR-10 does not take long to train to 25 epochs on modern consumer GPUs. I set up a grid search of 200 runs across reasonable dropout values, weight decay values, learning rate schedulesI assumed the quoted paragraph means the learning rate was decayed from to over the course of training., and whether weight decay was applied to normalization and bias termsAll hyperparameters can be seen in the appendix.. Like the Table 1 results, I only use the GCU activation functions in the mini-VGG convolutional blocks, using ReLU in the in the model head’s feed forward network.
I also created a small ResNet9 model to see how the GCU activation performs on a more modern model. Unlike the mini-VGG model, the ResNet9 model does not have an activation function in the head of the model, so it is a pure GCU model. Following a manual hyperparameter search to establish bounds, I trained it using standard CIFAR-10 settings, with a batch size of 512, One CycleLeslie N. Smith and Nicholay Topin. 2017. Super-Convergence: Very Fast Training of Neural Networks Using Large Learning Rates. arXiv:1708.07120. Schedule, and using the AdamWIlya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. arXiv:1711.05101. optimizer.
To reduce training time, I excluded SiLU from the activation function comparison. All models were trained using PyTorch’s Automatic Mixed PrecisionThe mini-VGG model with the GCU activation function was less stable in full precision. and were initialized and trained using the same seed, I used a FFCV DataLoader, channels last memory format, and TorchScript to accelerate the training process. I applied a standard set of CIFAR augmentations to all models: flip, translate, and cutout.
# Mini-VGG Results
I reproduce the polar plot of 147 runs of the mini-VGG grid search in Figure 2. It is inconclusive but we can see that some of the search parameters are suboptimalSuch as the VGG default dropout of .. The important column to look at is the Activation column which has all four activation functions: GCU+ReLU (gcuh), Mish, Mish+ReLU (mishh), and ReLU. Interestingly, my results all beat the paper’s validation accuracy by five percentage points.
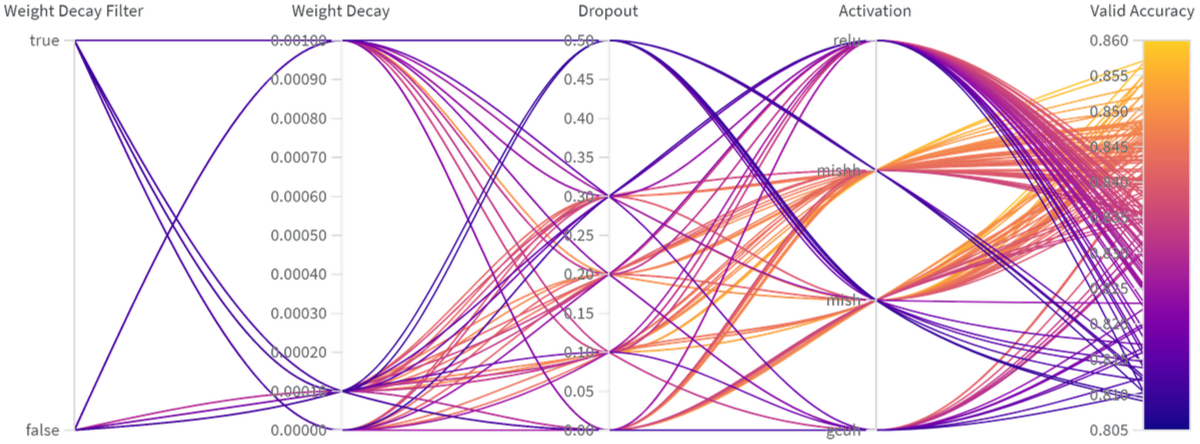
This plot shows that GCU might be underperforming Mish, but there is some overlap between top performing GCU models and bottom performing Mish results. It also shows there is a good amount of overlap between GCU models and ReLU models. GCU+ReLU scores a maximum of 84.15% valid accuracy while the maximum validation accuracy for Mish+ReLU, Mish, and ReLU was 85.71%, 85.68%, and 83.96%, respectively.
These are all single runs so it’s possible that these results are due to the single fixed seedDue to GCU using a different normalization then Mish and ReLU. and perhaps GCU validation accuracy will improve relative to Mish if I average the results over five seeded runs.
To reduce training time, I picked the top performing hyperparameters for all four activation functions and re-ran the grid search across 16 iterations. I show the results in Table 2 below.
Validation mini-VGG CIFAR-10 Results
| Accuracy | ||||
|---|---|---|---|---|
| Activation | Dropout | Weight Decay | Mean | StDev. |
| ReLU | 0.2 | 0.0010 | 83.55% | 0.18% |
| 0.0001 | 83.32% | 0.27% | ||
| 0.1 | 0.0010 | 83.99% | 0.18% | |
| 0.0001 | 83.55% | 0.19% | ||
| Mish+ReLU | 0.2 | 0.0010 | 85.22% | 0.15% |
| 0.0001 | 84.69% | 0.13% | ||
| 0.1 | 0.0010 | 85.36% | 0.18% | |
| 0.0001 | 84.75% | 0.18% | ||
| Mish | 0.2 | 0.0010 | 85.46% | 0.24% |
| 0.0001 | 85.18% | 0.22% | ||
| 0.1 | 0.0010 | 85.65% | 0.15% | |
| 0.0001 | 84.76% | 0.18% | ||
| GCU+ReLU | 0.2 | 0.0010 | 78.68% | 6.66% |
| 0.0001 | 75.09% | 6.27% | ||
| 0.1 | 0.0010 | 80.72% | 4.02% | |
| 0.0001 | 78.75% | 2.04% | ||
Five runs of 25 epochs on my implementation of the custom mini-VGG network.
GCU+ReLU does not come close to matching any of the other activation functions on average CIFAR-10 validation accuracy averaged across five seeded runs. Furthermore, the large standard deviations seem to indicate that GCU is an unstable activation function compared to more standard activation functions like ReLU and MishEven if GCU occasionally outperforms ReLU, ReLU would be preferred due to its stability advantage.. This result either provides additional confirmation that my replication setup and hyperparameters are not the same as the original paper and if I used that setup GCU might work, or is further evidence that the Noel et al results are not reproducible.
# ResNet Results
The ResNet9 gird search was across 45 hyperparameter permutationsThe hyperparameters chosen can be seen in the appendix. and unlike the mini-VGG results, the ResNet results shown in Figure 3 are quite conclusive.

The GCU validation accuracy is not close to the validation accuracy of Mish or ReLU ResNet models. Mish and ReLU score between 91-92% validation accuracy while GCU peaks at 76.76% accuracy. The ResNet differences are so far apart I declined to average multiple runs together.
This could be because the hyperparameters are offAn obvious hyperparameter would be the learning rate, but I chose these learning rates by manually sampling learning rates on a GCU ResNet9. All other learning rates I tried, both higher and lower, were worse., but if GCU is supposed to outperform Mish and ReLU I would expect it should at least be in the same ballpark as the mini-VGG results.
Perhaps these ResNet results shed some light on why Noel et al only reported VGG results.
# Conclusion
Due to the lack of training details provided by Noel et al, I cannot conclusively state that Growing Cosine Unit is unreproducible. However, I have not been able to replicate the CIFAR-10 results in the paperI declined to try CIFAR-100 or Imagenette training, as I assume the results will be similar.. My mini-VGG model on average had higher validation accuracy than Noel et al’s reported accuracies, but I did not find that GCU, either in the form of GCU+ReLU or GCU, outperformed Mish or ReLU across the mini-VGG and ResNet9 architectures.
# Appendix: Mini-VGG
The following PyTorch model is my interpretation of the Noel et al’s mini-VGG used for the CIFAR training. This reconstruction is from the model chart in the paper’s appendix.
class CifarVGG(nn.Module):
def __init__(self, num_classes=10, act_cls=nn.ReLU, hct_cls=nn.ReLU, drop=0.5):
super().__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=1, padding=1),
act_cls(),
nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=0),
act_cls(),
nn.MaxPool2d(2),
nn.Dropout(drop),
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),
act_cls(),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=0),
act_cls(),
nn.MaxPool2d(2),
nn.Dropout(drop),
nn.Flatten(),
nn.Linear(2304, 512),
hct_cls(),
nn.Dropout(drop),
nn.Linear(512, num_classes)
)
def forward(self, x):
return self.model(x)
# Appendix: Grid Search
The following code defined my initial search space for the min-VGG and ResNet9 models using Optuna’s BruteForceSampler.
act_cls = trial.suggest_categorical('act_cls', ['gcuh', 'mish', 'mishh', 'relu'])
if act_cls != 'mishh':
arch = trial.suggest_categorical('arch', ['resnet', 'vgg'])
else:
arch='vgg'
if model=='vgg':
drop = trial.suggest_categorical('drop', [0., 0.1, 0.2, 0.3, 0.5])
schedule = trial.suggest_categorical('schedule', ['LinearLR', 'CosineAnnealingLR'])
batch_size = 256
optimizer = 'rmsprop'
lr = 1e-4
else:
schedule = 'OneCycleLR'
batch_size = 512
model = 'resnet'
optimizer = 'adamw'
lr = trial.suggest_categorical('lr', [3e-3, 5e-3, 8e-3])
drop = 0
weight_decay = trial.suggest_categorical('weight_decay', [1e-4, 1e-3, 0.])
if weight_decay > 0:
wd_filter = trial.suggest_categorical('wd_filter', [True, False])
else:
wd_filter = True
And this is the Optuna code to define the five epoch mini-VGG validation search space.
arch='vgg'
batch_size = 256
optimizer = 'rmsprop'
lr = 1e-4
schedule = 'CosineAnnealingLR'
wd_filter = True
seeds = [42, 314, 1618, 2998, 2077]
weight_decay = trial.suggest_categorical('weight_decay', [1e-4, 1e-3])
drop = trial.suggest_categorical('drop', [0.1, 0.2])
act_cls = trial.suggest_categorical('act_cls', ['gcuh', 'mish', 'mishh', 'relu'])
Full code to replicate these results is available on GitHub.