While recent releases of open and closed language modelsAnd models like Llama finetunes which are somewhere in-between. have emphasized the large in Large Language Models (LLM), most everyday NLP work is done with far more modest language models, finetuned on custom or task specific datasets.
In this post, I will show via benchmark examplesA table with the final results can be found in the conclusion except for FlashAttention which has a separate table. how to achieve fast finetuning performanceFor the best downstream task performance, models may need to be trained using a different precision then the fastest precision. on modern GPUs using tools like PyTorch 2.0’s torch.compile and FlashAttentionTri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In Advances in Neural Information Processing Systems..
# Setup
To benchmark finetuning performance on consumer GPUs, I decided to use the the most popular model on the Hugging Face Hub: BERT base (uncased)Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 4171–4186. DOI:10.18653/v1/N19-1423. I paired BERT with a common NLP finetuning dataset: IMDBAndrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, 142–150..
All BERT finetunes are trained on the same Nvidia RTX 3080 Ti, an Ampere card with 12GB of RAM, Tensor Cores, and support for BFloat16 and TensorFloat32 formatsInformation about various floating point types used in modern deep learning can be found in the appendix.. To mitigate an effect of the hardware lottery, I limit the boost clock to the stock setting of 1665 MHz.
I train all models for two epochs across an 8,000 sample from the training and validation datasets. I use a padded sequence length of 256 tokens, the AdamWIlya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. arXiv:1711.05101. optimizer, cosine decay learning rate schedule with a linear warmup, a weight decay of , and an initial batch size of 40 and initial learning rate of .
In addition to the standard Hugging Face libraries such as Transformers and Datasets, I used Mosaic’s Composer to train all models. Source code for replicating these experiments and viewing original results can be found here.
# Full Precision Baseline
First, we’ll establish a baseline with full precision Float32 training by passing 'fp32' to the Composer trainerBy default, Composer will train in Float16 Mixed Precision unless precision=fp32 is passed to the trainer.. This will result in the slowest training time, but will be the most numerically stable. With a sequence length of 256, BERT base can fit a batch size of 40 in 12GB of RAM.
trainer.fit(precision='fp32')
This results in a respectable performance of ~136 samples per second.
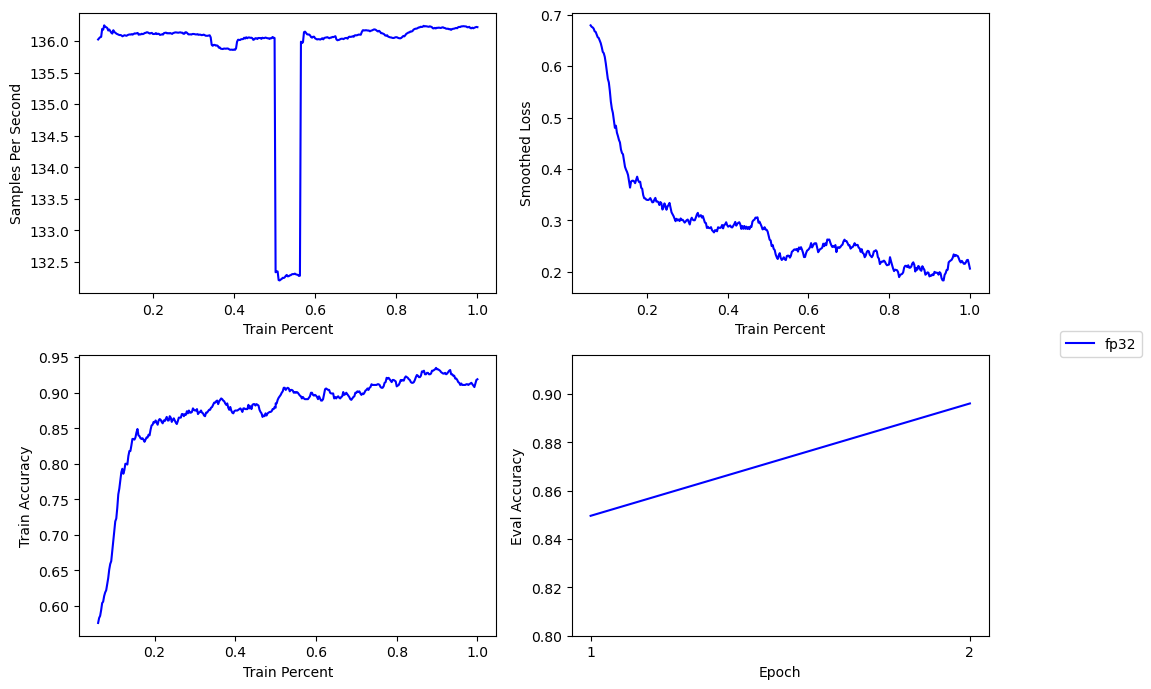
The drop in performance in the middle occurs due to switching to and from the validation dataloader.
# Small Full Precision Speedups
In this next section I will cover two small full precision speedups which will be more useful later on. These changes won’t have a large effect since the majority of the time spent training our BERT model is on slow Float32 operations. But these speedups will persist and improve as more training bottlenecks are removed.
# ForEach Fused Optimizer
Next we’ll switch from the default AdamW optimizer to a vertically fused optimizer, using PyTorch ForEach methods. ForEach optimizers can be significantly faster then standard optimizers. I’ve benchmarked my fastai ForEach implementations to be 21 to 293 percent faster on the optimizer step across various models.
optimizer = AdamW(
params=composer_model.parameters(),
...,
ForEach=True
)
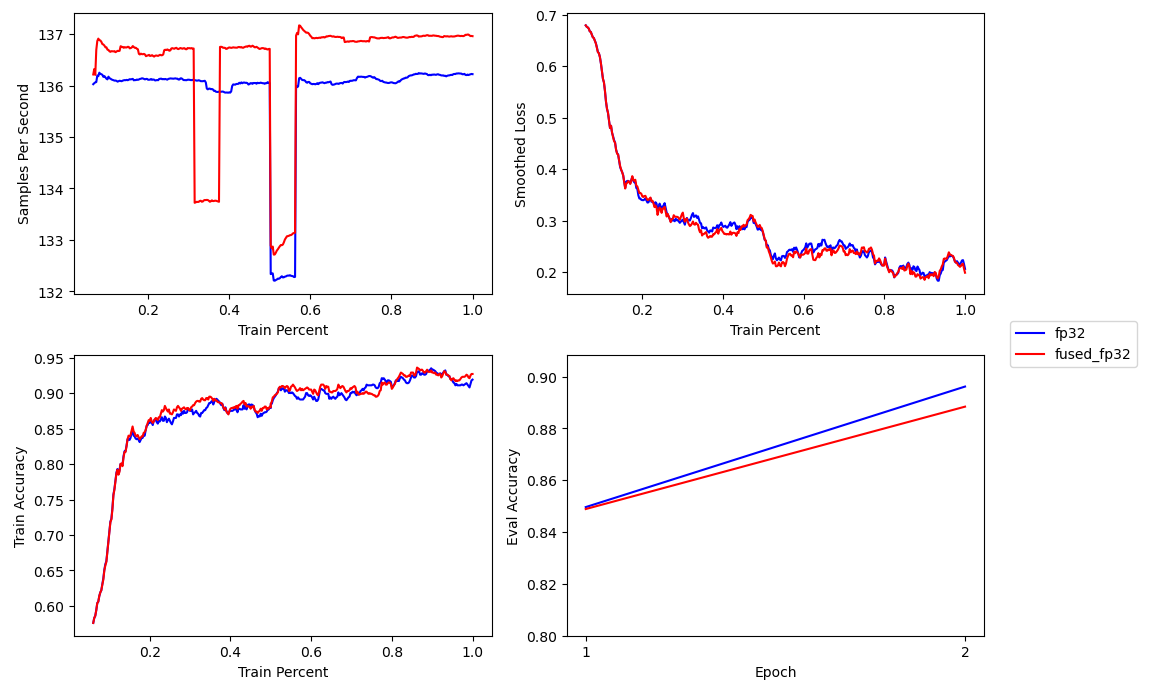
In this case, the AdamW optimization step for BERT base is reduced from ~20ms to ~9msAs measured on a fastai, blurr, and fastxtend run using fastxtend’s Simple Profiler callback., which results in a 1 sample per second increase with full precisionI’m not sure what caused the random drop in performance during the first epoch. But it persisted across multiple training runs..
# TensorFloat32 Matrix Multiplications
Ampere or newer GPUsThe A100, RTX 3000 series, H100, RTX 4000 series GPUs, and Ampere and Ada Lovelace professional GPUs. can use a new Nvidia floating point format, TensorFloat32For more information on TF32, check out the appendix., which has the precision of Float32 but can use tensor cores for faster operations. By default, PyTorch enables TensorFloat32 for convolutional operations but uses Float32 for matrix multiplicationsFrom PyTorch 1.7 to PyTorch 1.11, TF32 MatMuls was turned on by default.. To use set either of these options:
torch.set_Float32_matmul_precision('high')
# or
torch.backends.cuda.matmul.allow_tf32 = True
The results should hopefully be the same and perhaps a bit faster. And the plot below confirms both.
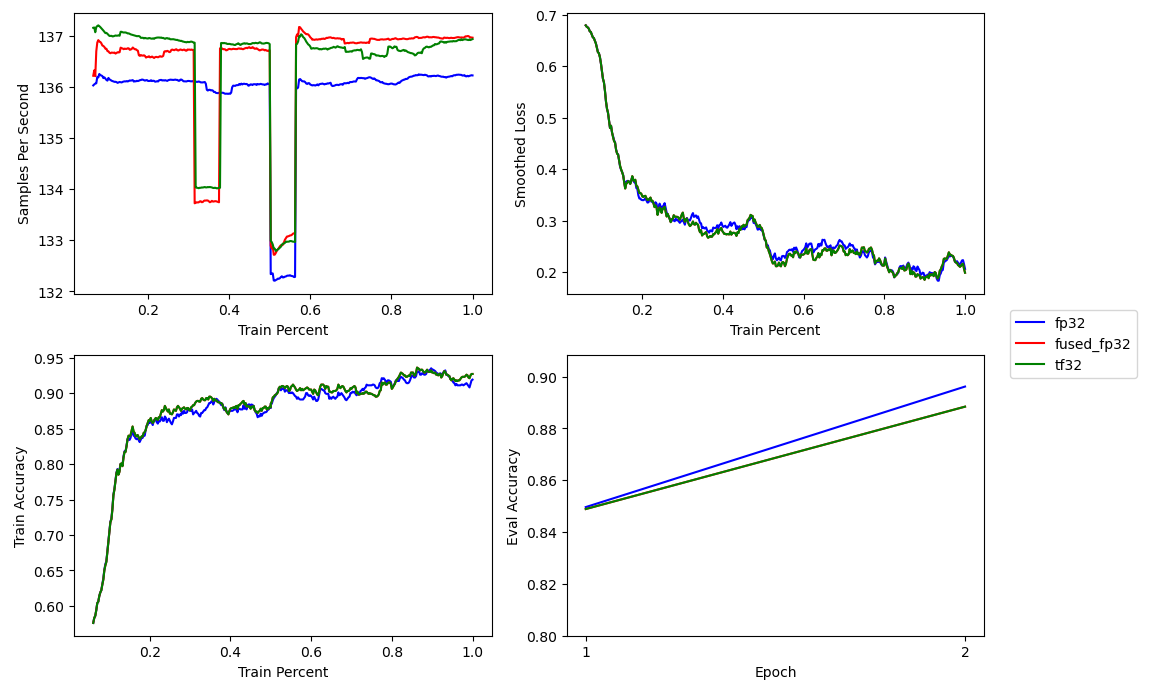
With the training loss and validation accuracy is exactly the same as the prior run. And maybe if one ignores the second epoch, the TF32 matrix multiplications are a bit faster.
# Automatic Mixed Precision
The first major speedup comes from using automatic mixed precision training. Modern GPUs have tensor coresFor Nvidia GPUs: Volta, Turing, Ampere, Hopper, and Ada Lovelace architectures all have Tensor Cores. Along with all of Intel’s Arc GPUs. AMD GPUs appear to have something similar in RDNA 3 GPUs., which can greatly speed up operations in non-full precision formats.
An across the board reduction in precision can have undesired effects on numerical stability, so automatic mixed precision training performs some operations in half precision, some in full precision, and keeps a copy of the model parameters in full precision for the optimization step.
# Float16 Mixed Precision
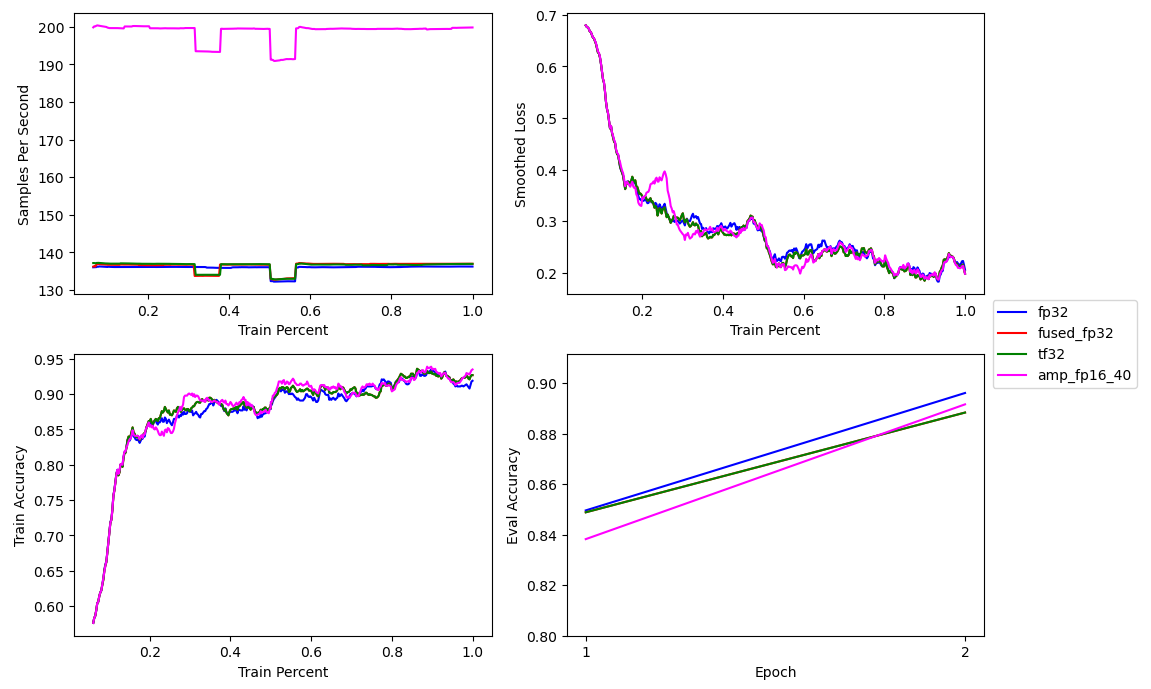
By default, Composer uses Float16 mixed precision, but we can also specify it by setting the trainer’s precision to 'amp_fp16'. We also keep the matrix multiplications in TensorFloat32 format.
torch.set_Float32_matmul_precision('high')
trainer.fit(precision='amp_fp16')
The combination of mixed precision, TF32 matmuls, and a fused optimizer increases the BERT base training speed from ~136 to ~200 samples per second, a 47 percent improvement, while retaining a similar loss curve and validation accuracy.
# Increase Batch Size
Since mixed precision is using both 16-bit and 32-bit operations, this means it’s using less memory then pure 32-bit training. So we can train on a large batch size and gain even more performanceIf you are using an older GPU mixed precision is still useful due to the memory savings. The subsequent larger batch size can yield a modest increase in performance.. The next plot show the increase in batch size from 40 to 56.
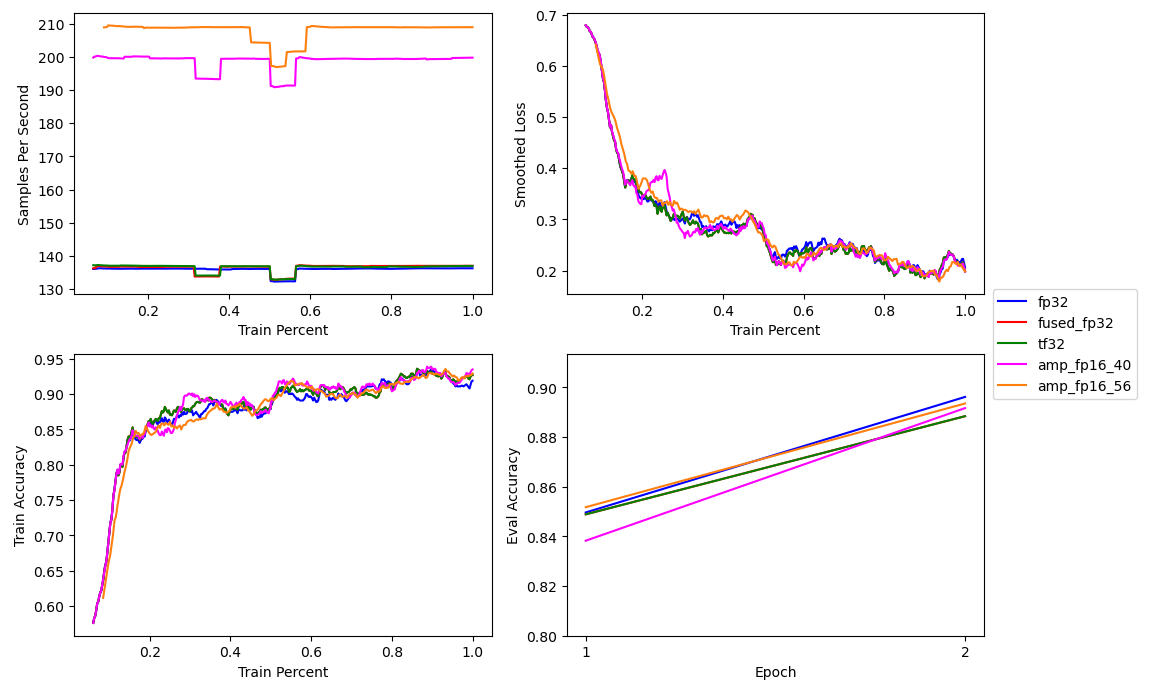
The increase in batch size results in a further performance gain to ~209 samples per second, a 54 percent improvement.
# BFloat16 Mixed Precision
If Float16 mixed precision results in numerical instability, or the model you are using was trained in BFloat16 mixed precisionBFloat16 has the same range as Float32, so unlike Float16 AMP it doesn’t require a gradient scaler., you can also use it to increase training speed. Provided you have an Ampere or newer GPU.
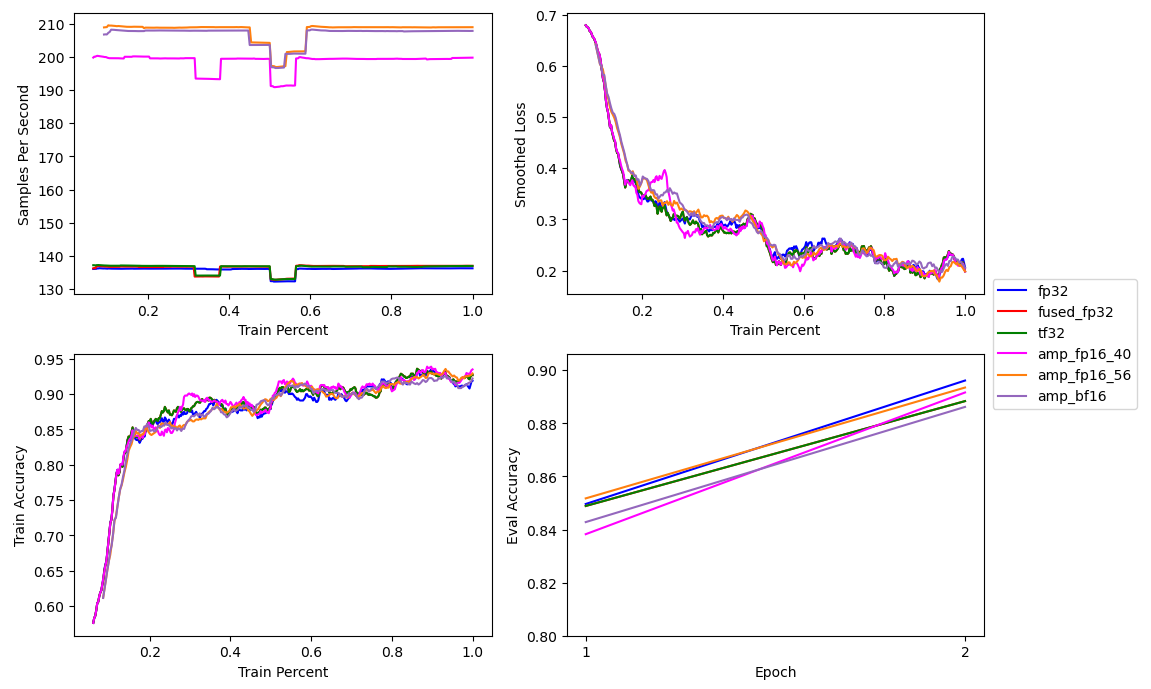
Composer supports BFloat16 mixed precision with 'amp_bf16'. I also set the matrix multiplication precision to bFloat16 using the 'medium' option.
torch.set_Float32_matmul_precision('medium')
trainer.fit(precision='amp_bf16')
This resulted in almost the same training speed (~208 samples per second) as Float16 mixed precision, and slightly less accuracyPresumably due to the lower matrix multiplication precision..
# PyTorch Compile
torch.compile is a new feature introduced in PyTorch 2.0 for training models faster on modern hardwareIn recent GPU generations, compute improvements have been lapping memory speed improvements, which means PyTorch’s eager mode isn’t as compute efficient as it has been on older hardware.. By default, torch.compile uses Triton to JIT-compile PyTorch code into fused and optimized Cuda kernels, increasing computational efficiency while reducing memory transfers and overheadFor more details on memory transfer and overhead, check out Horace He’s Making Deep Learning Go Brrrr From First Principles..
In Composer, enabling torch.compile with the default settings requires passing an empty dictionary to compile_config when initializing the trainerUsing torch.compile currently requires version 0.14 of Composer. At the time of running this section it was not released so I installed from source..
trainer = Trainer(compile_config={})
Then we call fit like before, keeping the matrix multiplication precision at TensorFloat32torch.compile will warn you if matrix multiplication precision is set to Float32..
torch.set_Float32_matmul_precision('high')
trainer.fit(precision='amp_fp16')
PyTorch will then JIT-compile BERT base three times. Once for the training pass and twice during the evaluation pass, once per all encountered batch sizes.
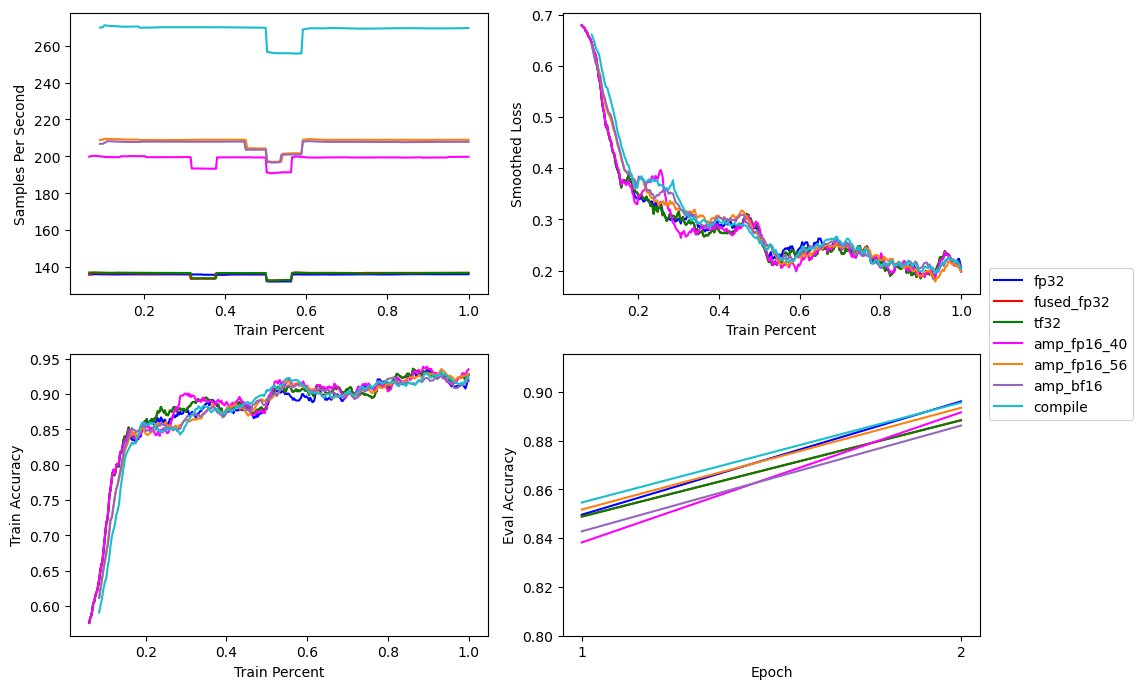
torch.compile with Float16 Automatic Mixed Precision at a Batch Size of 56Compiling BERT base results in a significant increase in training performance. Jumping from ~209 samples per second to ~270 samples per second.
# Increase Batch Size
Since we are not training with gradient checkpointing, each PyTorch operation stores an activation for calculating the gradients during the backward pass. Because torch.compile fuses multiple individual PyTorch operations into one compute kernelA process called operator fusion. where possible, this means the amount of GPU memory used for storing activations has been reduced.
So in addition to training faster, we can also increase the batch size from 56 to 64Decreasing the learning rate from at a batch size of 56 to resulted in better 2 epoch performance., resulting in an even faster ~280 samples per second.
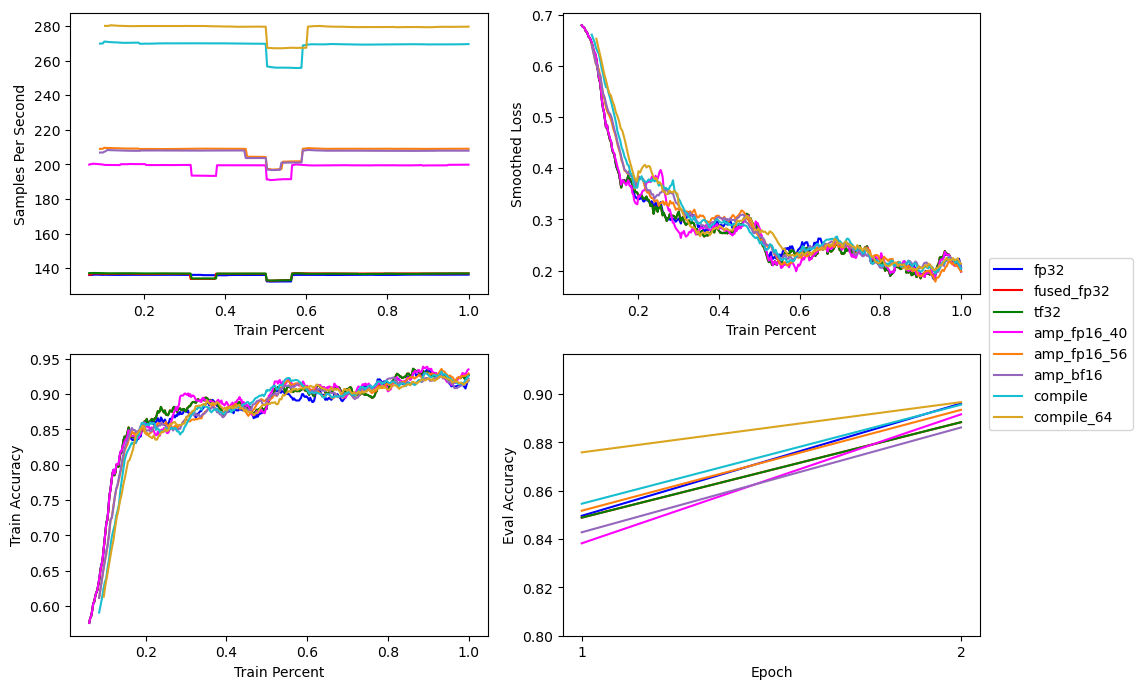
torch.compile with Float16 Automatic Mixed Precision at a Batch Size of 64With three changes to our training loop, a fused ForEach optimizer, Float16 mixed precision, and torch.compile we’ve more then doubled our model training throughput.
# Possible Improvements
With some hyperparameter tuning, the first set of changes to our model training procedure are a pareto improvement, with increased training throughput at a similar or better downstream performance. The next set of potential performance improvements are more likely to have negative effects, either on training speed or downstream performance. So they will need to be tested before applying them to your finetuning task.
# Apex Fused Optimizer
The fused ForEach optimizer already halved the optimization step time, so the next thing I tried was to use Nvidia’s Apex fused optimizer. But this led to a decrease in performance to ~278 samples per second.
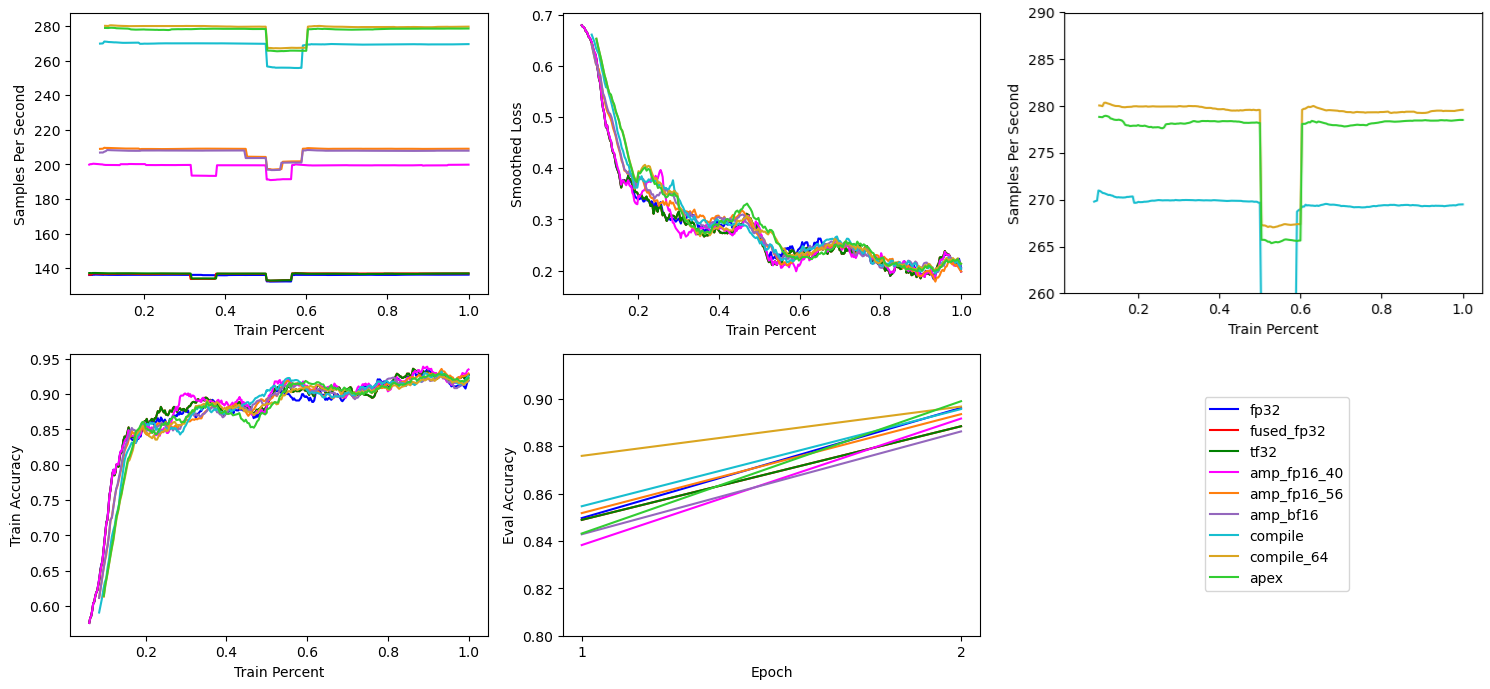
Unlike the ForEach fused optimizer used in the prior section, Apex’s AdamW is both horizontally and vertically fusedVertical fusion means the optimizer operations are combined resulting in as few operations per model layer as possible, horizontal fusion means applying the same operation across all model layers in parallel. Apex does both at the same time., so this result was surprising. Every time I’ve used Apex optimizers in the past, the combination of horizontal and vertical fusion made them the fastest optimizers.
# Apex Fused LayerNorm
While torch.compile provides a great performance boost, custom Cuda kernels can still be significantly faster than the Triton compiled codeAt the expense of a Cuda graph break using default torch.compile settings.. Composer has the FusedLayerNorm algorithm to automatically replace all instances of LayerNorm with an Apex fused LayerNorm.
trainer = Trainer(algorithms=[FusedLayerNorm()])
This change also allowed increasing the batch size to 72 due to requiring less memory.
Using Apex’s Fused LayerNorm increases training throughput to ~287 samples per second. However, it is not numerically stable in Float16 mixed precision at all.
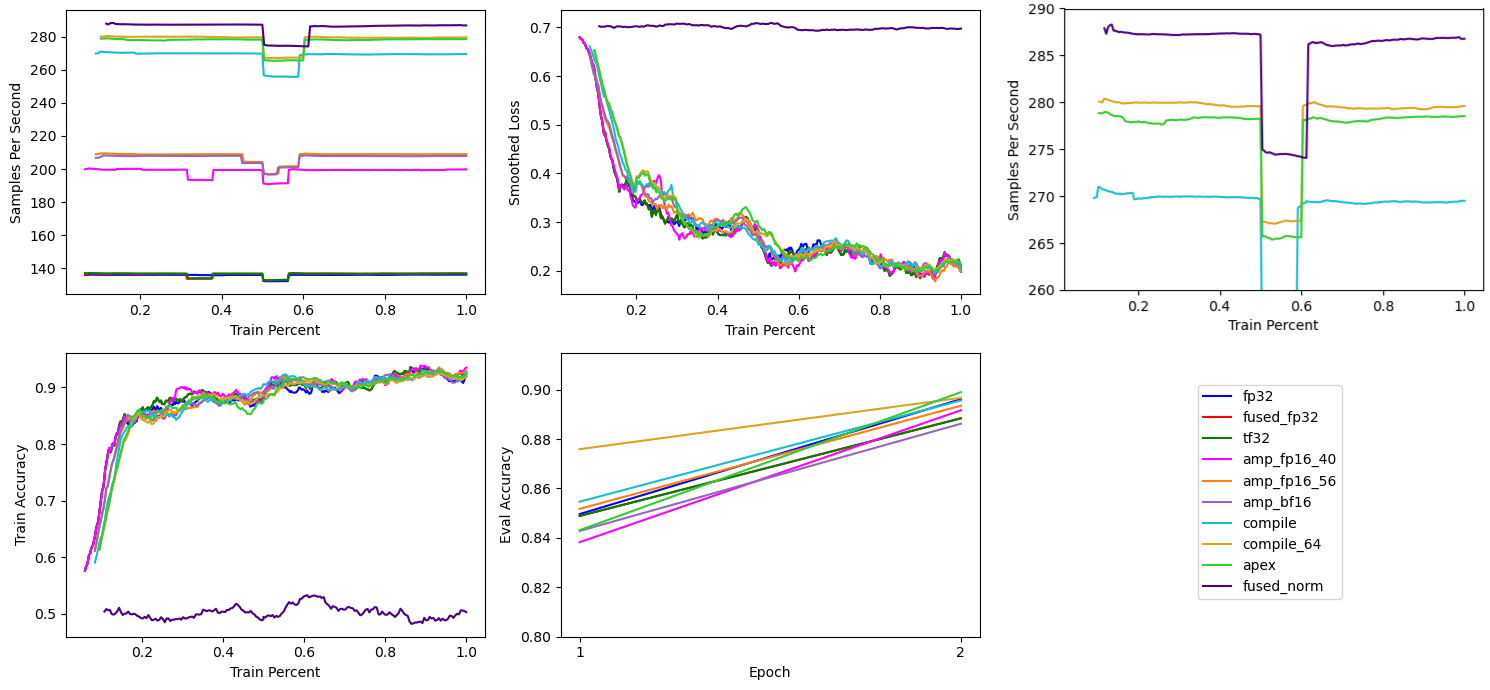
I’m not sure why it isn’t numerically stable, whether this result is specific to BERT base or the IMDB classification task, related to PyTorch 2.0 and/or Cuda 11.8 incompatibilities, or something else.
# Low Precision LayerNorm
Like many normalization layers, LayerNorm in mixed precision performs it’s calculations in Float32, slowing down the training process and using more GPU memory. Low precision normalization layers offer better performance at the possible cost of increased numerical instability due to less precision. Fortunately, operator fusion from torch.compile should limit the potential issue of numerical instability.
Like fused LayerNorm, Composer has the LowPrecisionLayerNorm algorithm to automatically replace all instances of LayerNorm with a low precision LayerNorm.
trainer = Trainer(algorithms=[LowPrecisionLayerNorm()])
Like fused LayerNorm, low precision LayerNorm allows increasing the batch size from 64 to 72.
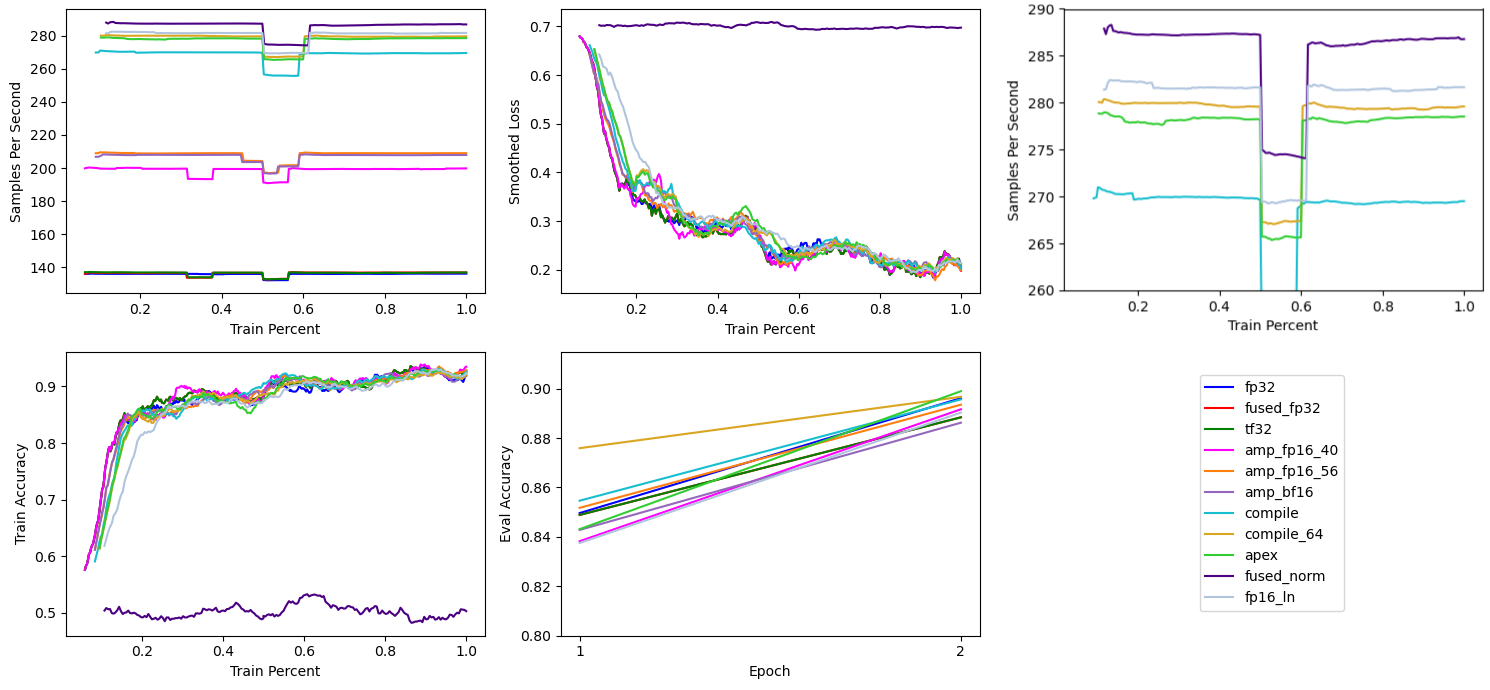
In this case, using low precision LayerNorm provides a modest increase in training performance to ~282 samples per second without any noticeable difference in numerical stability.
# 8-Bit Optimizer
In 8-bit Optimizers via Block-wise Quantization, Tim Dettmers et alTim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 2022. 8-bit Optimizers via Block-wise Quantization. 9th International Conference on Learning Representations, ICLR (2022). introduce a method for storing most of the optimizer’s gradient statistics in 8-bit values instead of 32-bit, saving memory and potentially increase optimizer computational speed. Dettmers also maintains the bitsandbytes Python package with efficient Cuda implementations of supported optimizers and other 8-bit and quantization methods.
bitsandbytes’ AdamW8bitDuring the writeup I realized I accidentally trained using Adam8bit instead of AdamW8bit, but according to the source code both use the AdamW formulation if a non-zero weight decay is used. is a drop in replacement for both PyTorch’s Adam and AdamW. Unfortunately in this case the memory savings from 8-bit AdamW was not enough to increase the batch size from 64 to 72.
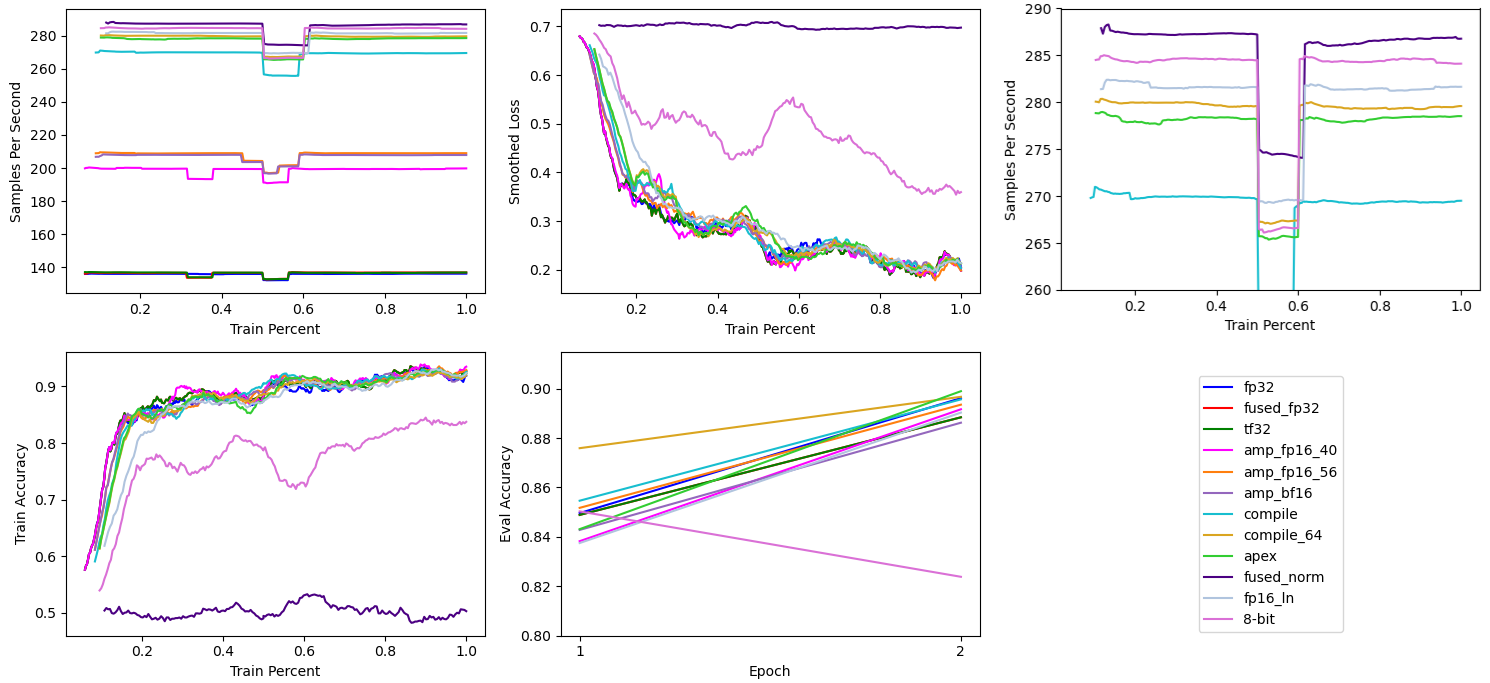
Training speed increased from ~280 to a hair under ~285 samples per second at the expense of a decrease in task performance. This decrease in task performance persisted whether I used PyTorch embeddings, bitsandbytes’ StableEmbedding, and across multiple learning rates.
# PyTorch Fused Optimizer
PyTorch 2.0 also brings a PyTorch native implementation of Apex’s fused Adam optimizer. However, it’s been reported that the first version has some teething issues, which the disappointing training performance evidently shows.
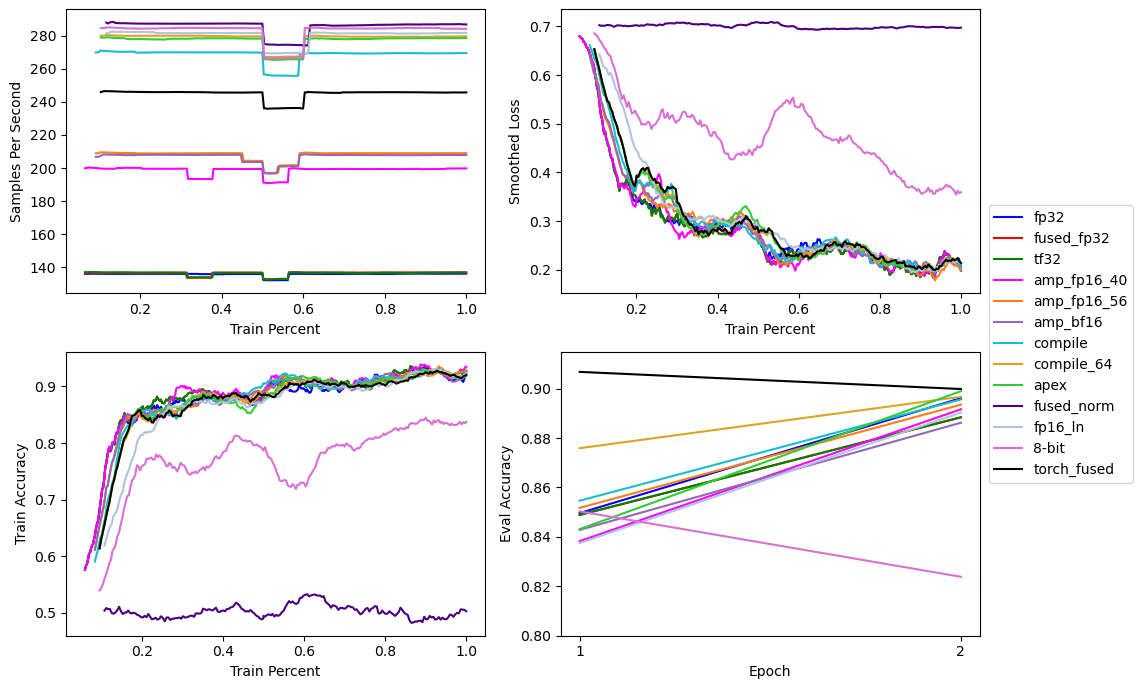
Hopefully the PyTorch 2.0.1 or 2.1 version will be more useful.
# 32-bit Fused Optimizer
bitsandbytes also has 32-bit versions of fused optimizers. In the past these versions have been slightly slower then the Apex implementations. They are however, easier to install, as they are precompiled.
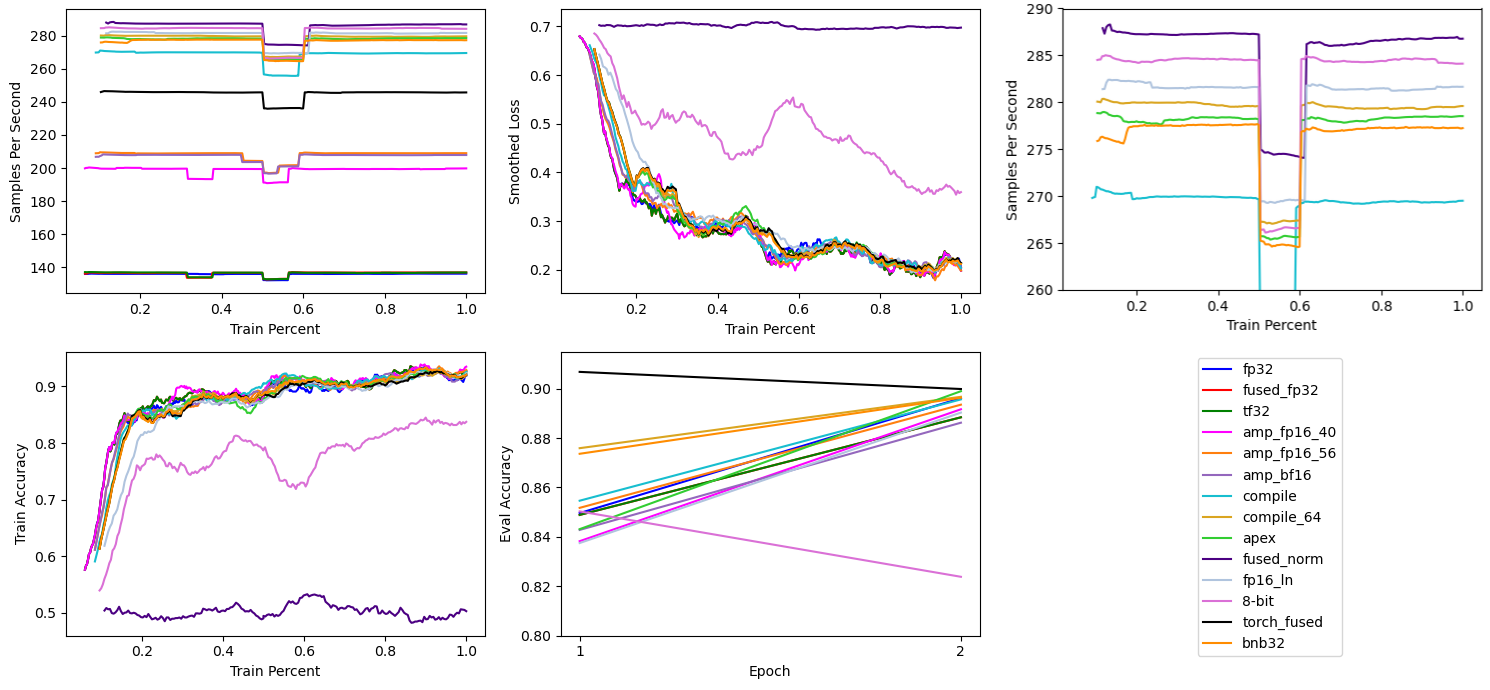
This benchmark shows them at ~277 samples per second, a hair slower then Apex’s fused optimizers. Still curiously slower then the ForEach fused optimizer.
# 8-Bit Adam & Low Precision LayerNorm
Finally, I provide a benchmark of 8-Bit AdamW with low precision LayerNorm. Individually, both 8-Bit AdamW and low precision LayerNorm provided an increase in training thourghput, so one would expect them to do the same together.
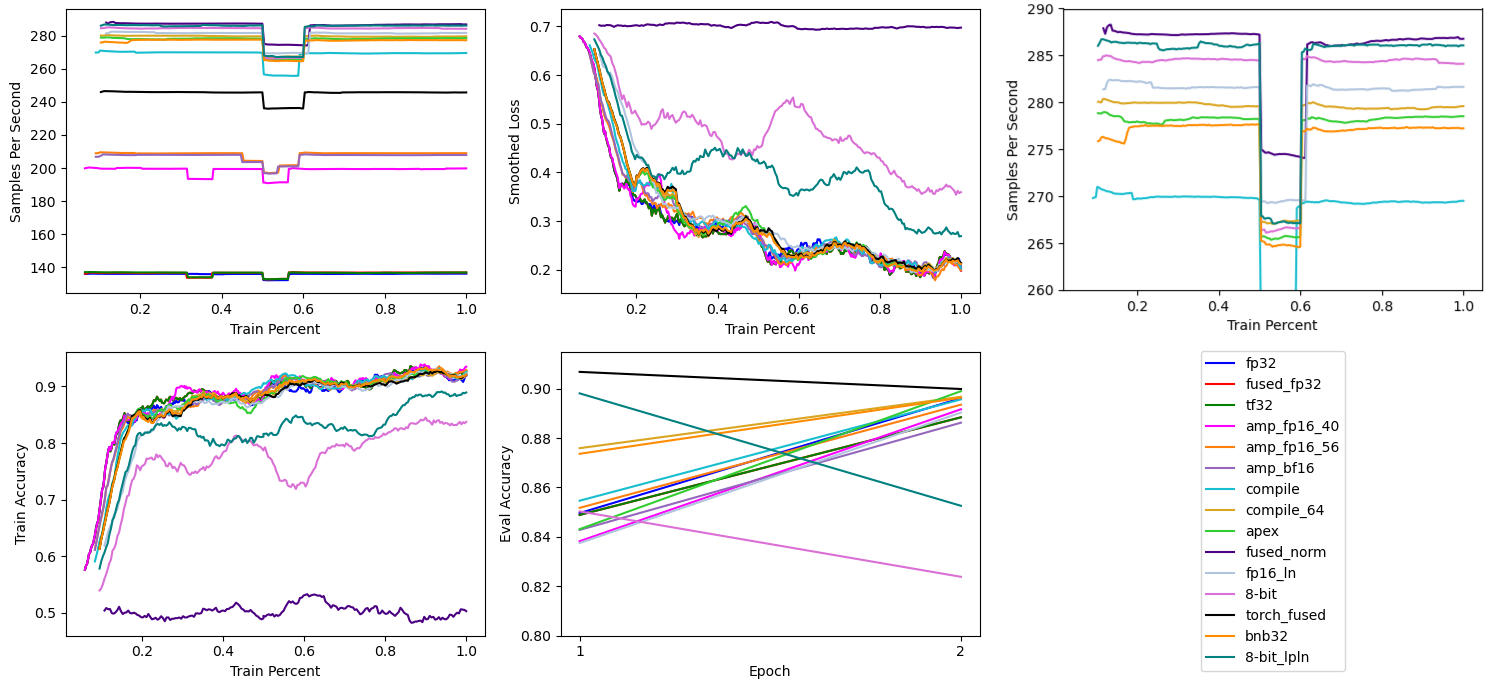
Which is what the chart above shows. 8-Bit AdamW and low precision LayerNorm together provide the second fastest modification to the mixed precision and torch.compile setup at ~286 samples per second.
# Near Future Improvements
This next section discusses potential performance increases which can be achieved now, assuming you are using the correct model of have the latest hardware. But for many, these training speed increases will be realized in the near future.
# FlashAttention
FlashAttention is a hardware optimized implementation of the Transformer’s attention mechanism. 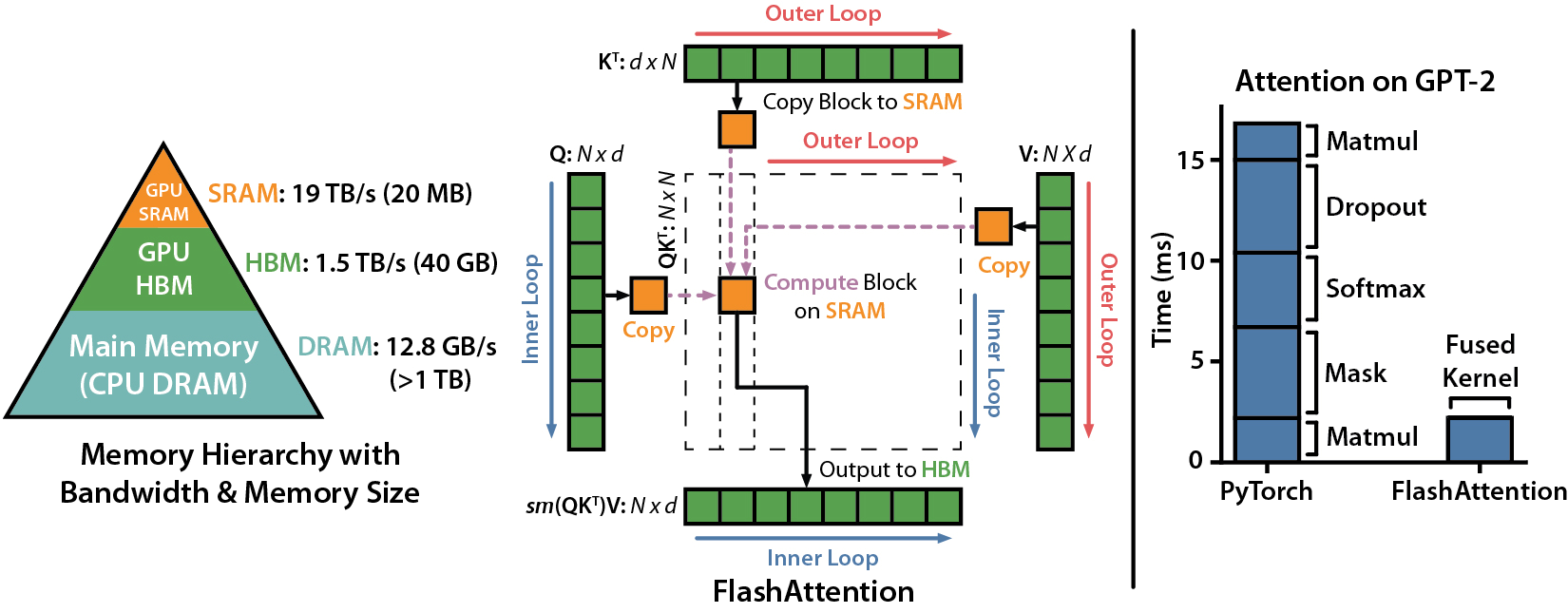
At the time of writing, only a handful of pretrained models in the Hugging Face Hub appear to use FlashAttention, and only one which is small enough for finetuning on consumer GPUs is MosaicBERT. MosaicBERT appears to use a custom Triton implementation of FlashAttention, instead of the original Cuda implementation, the original Triton version, or PyTorch native implementation, which is incompatible with the version of Triton that PyTorch 2.0 uses.
The original and PyTorch FlashAttention implementations have finetuning issues too: they don’t support BERT style masking for padded sequencesFlashAttention has an outstanding PR which I think would add BERT masking for padded sequences.. Additionally, the FlashAttention BERT implementation is the first PyTorch model I’ve ran into which torch.compile has errored out .
Instead of finetuning, I decided to benchmark MLM pretraining with BERT and FlashAttention, modifying the Hugging Face implementation of BERT to use PyTorch’s FlashAttentionPyTorch’s scaled_dot_product_attention also is tested to work with torch.compile.. I only benchmark using Float16 AMP, and show AMP, torch.compile, FlashAttention, and FlashAttention with torch.compile.
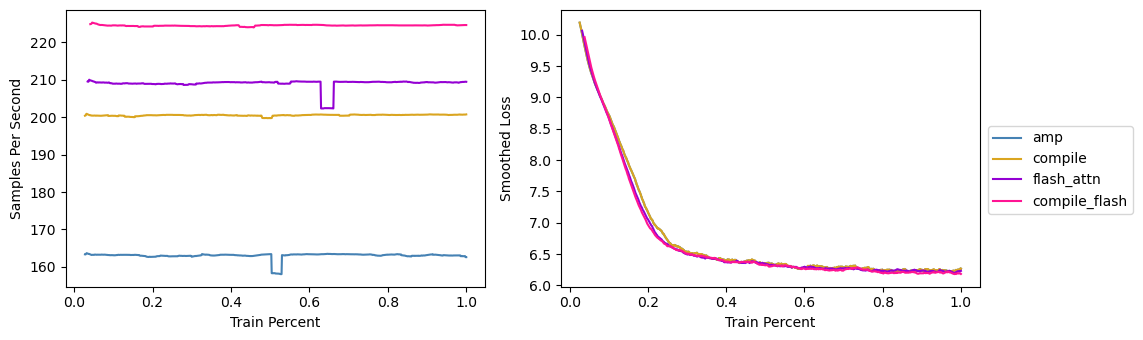
FlashAttention yields significant speedups, outperforming torch.compile in eager mode. Additionally, the memory savings from FlashAttention allow for increasing the batch sizeBy itself torch.compile reduced memory usage, but it wasnt enough to increase the batch size.. This combination of increased batch size and faster computation due to FlashAttention and torch.compile results significantly faster training, as shown in Table 1 below.
BERT MLM Pretraining with AMP, Compile, and FlashAttention
| Method | Samples per Second | Speedup | Batch Size | Learning Rate | Wallclock Time |
|---|---|---|---|---|---|
| AMP | ~163 | - | 32 | 5e-5 | 188 |
| Compile | ~200 | 23% | 32 | 5e-5 | 171 |
| FlashAttention | ~209 | 28% | 40 | 7.5e-5 | 147 |
| FlashAttention+Compile | ~224 | 37% | 48 | 1e-4 | 152 |
All models trained in FP16 AMP. Speedup is calculated for each method relative to the AMP baseline. Wallclock time is in seconds.
When finetuning a pretrained model, be on the lookout for models which use FlashAttention or can be easily modified to use FlashAttention.
# Float8 Training
The release of Nvidia’s Hopper and Ada Lovelace GPUs brings hardware support for Float8 mixed precision Transformer trainingAt the time of writing, software support is limited to Hopper GPUs.. I cannot test this myself, but fortunately Mosaic already benchmarked Float8 training on a GPT model using H100s. Depending on the model size, the combination of BFloat16 plus Float8 mixed precision was 0.5-0.6x faster then just BFloat16 mixed precision.
Speedups will likely be slower on consumer hardware since the performance increase appears to scale with model size, but if you have an Ada Lovelace GPU this is something to look forward to once library support extends to non-server GPUs.
# Conclusion
If maximum training speed is desired, use a ForEach Fused Optimizer, TensorFloat32 Matrix Multiplications, Float16 or BFloat16 Mixed Precision, and torch.compile as these will be numerically stable on most models and tasks. With BERT Base on a 3080 Ti, we see that the four items combined lead to a 106% improvementAlthough wallclock time can increase due to torch.compile if finetuning on a very small dataset like the 8,000 samples of IMDB that I used for this post. in training speed over Float32 finetuning.
If supported, FlashAttention should be added to all model training. The MLM pretraining benchmark showed FlashAttention adds an additional 15 percentage points of throughput to a compiled model on a 3080 Ti, with a potential for an additional 5 percentage point improvement if Cuda graph breaks are avoided.
Outside of the five additional potential performance improvements, Low Precision LayerNorm & 8-Bit Adam look worth testing to see if they are numerically stable for your particular model and finetuning task.
BERT Finetuning with AMP, Compile, and Potential Improvements
| Method | Samples per Second | Speedup | Batch Size | Learning Rate | Wallclock Time | Stable Training |
|---|---|---|---|---|---|---|
| Float32 | ~136 | - | 40 | 1e-4 | 154 | Yes |
| ForEach Optimizer | ~137 | - | 40 | 1e-4 | 153 | Yes |
| TensorFloat32 MatMul | ~137 | - | 40 | 1e-4 | 153 | Yes |
| Float16 AMP | ~200 | 47% | 40 | 1e-4 | 104 | Yes |
| Float16 AMP | ~209 | 54% | 56 | 1.5e-4 | 100 | Yes |
| BFloat16 AMP | ~208 | 53% | 56 | 1.5e-4 | 102 | Yes |
| Compile | ~270 | 99% | 56 | 1.25e-4 | 107 | Yes |
| Compile | ~280 | 106% | 64 | 1.25e-4 | 105 | Yes |
| Apex Optimizer | ~278 | 104% | 64 | 1.25e-4 | 105 | Yes |
| Fused LayerNorm | ~287 | 111% | 72 | 1e-4 | 99 | No |
| Low Precision LayerNorm | ~282 | 107% | 72 | 1.35e-4 | 106 | Yes |
| 8-Bit Adam | ~285 | 110% | 64 | 8e-5 | 105 | No |
| PyTorch Fused Opt | ~245 | 80% | 64 | 1.25e-4 | 113 | Yes |
| BNB 32-bit Fused Opt | ~277 | 104% | 64 | 1.25e-4 | 106 | Yes |
| 8-Bit Adam + Low Precision LayerNorm | ~286 | 110% | 72 | 1.25e-4 | 108 | No |
Prior to Apex Optimizer, all changes (except BFloat16) are additive. Starting with Apex Optimizer, all changes are in addition to FP16 AMP, TF32 MatMuls, ForEach Opt, & Compile. Speedup is calculated for each method relative to the Float32 baseline. Wallclock time is in seconds.
# Appendix: Floating Types
Here I provide a reference table for the six standard floating point types used in deep learning.
Floating Point Format Overview
| Format | Abbreviation | Bits | Exponent | Mantissa | Range | Precision | A100 Speedup |
|---|---|---|---|---|---|---|---|
| Float32 | FP32 | 32 | 8 | 23 | ~1.18e-38 to ~3.40e38 | 6-9 digits | 1x |
| Float16 | FP16 | 16 | 5 | 10 | ~6.10e-5 to ~6.55e4 | 3-4 digits | 16x |
| BFloat16 | BF16 | 16 | 8 | 7 | ~1.18e-38 to ~3.40e38 | 2-3 digits | 16x |
| TensorFloat32 | TF32 | 32 | 8 | 10 | ~1.18e-38 to ~3.40e38 | 3-4 digits | 8x |
| Float8 E4M3 | FP8 E4M3 | 8 | 4 | 3 | ~1.95e-3 to 448 | ~1 digit | N/A |
| Float8 E5M2 | FP8 E5M2 | 8 | 5 | 2 | ~1.53e-5 to ~5.73e4 | ~1 digit | N/A |
FP8 E4M3 and FP8 E5M2’s precision ranges from 0 digits to a maximum of three for magic numbers, with an average near 1. A100 Speedup is Nvidia’s reported A100 tensor core speedup without any overhead.
TensorFloat32 is a hybrid type introduced by Nvidia in the Ampere architecture GPUs. Storage is in FP32 with a hybrid computation:
TF32 is a new compute mode added to Tensor Cores in the Ampere generation of GPU architecture. Dot product computation, which forms the building block for both matrix multiplies and convolutions, rounds FP32 inputs to TF32, computes the products without loss of precision, then accumulates those products into an FP32 output.
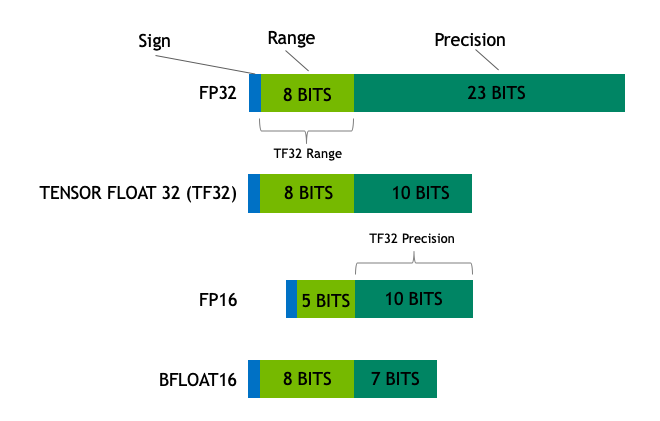
Float8 is a new (dual) format which Nvidia introduced with the Hopper and Ada Lovelace generation of GPUs. Both E4M3 and E5M2 are used during training:
During training neural networks both of these types may be utilized. Typically forward activations and weights require more precision, so E4M3 datatype is best used during forward pass. In the backward pass, however, gradients flowing through the network typically are less susceptible to the loss of precision, but require higher dynamic range. Therefore they are best stored using E5M2 data format.
