Over the past week, Thomas Capelle and I discovered, debugged, and created a workaround for a performance bug in PyTorch which reduces image training GPU throughput up to forty percentTo realize the full performance decrease, one needs to be training on an Ampere GPU in channels last format..
This performance bug has been affecting fastai for an unknown amount of time.
The culprit? Subclassed tensors.
# Subclassed Tensors Reduce Throughput
To achieve this loss in PyTorch performance, all one needs to do is create a new passthrough class which inherits from torch.Tensor and cast any input tensors to this class using torch.Tensor.as_subclass before sending them to the model for the forward passA simplified subclassing training loop is in the appendix. The full code for reproduction is available here..
class SubClassedTensor(torch.Tensor):
pass
This results in a ~150-200 images/second decrease in GPU throughput across VoltaUsing a Google Cloud V100 instance. and Ampere generations compared to a training step using torch.Tensor. In channels last format, the throughput difference increases to ~370-400 images/second on a 3080 TiUsing a runpod.io 3080 Ti community instance.. Both examples use a torchvision ResNet50, 224-pixel image size, batch size of 64, and mixed precision.
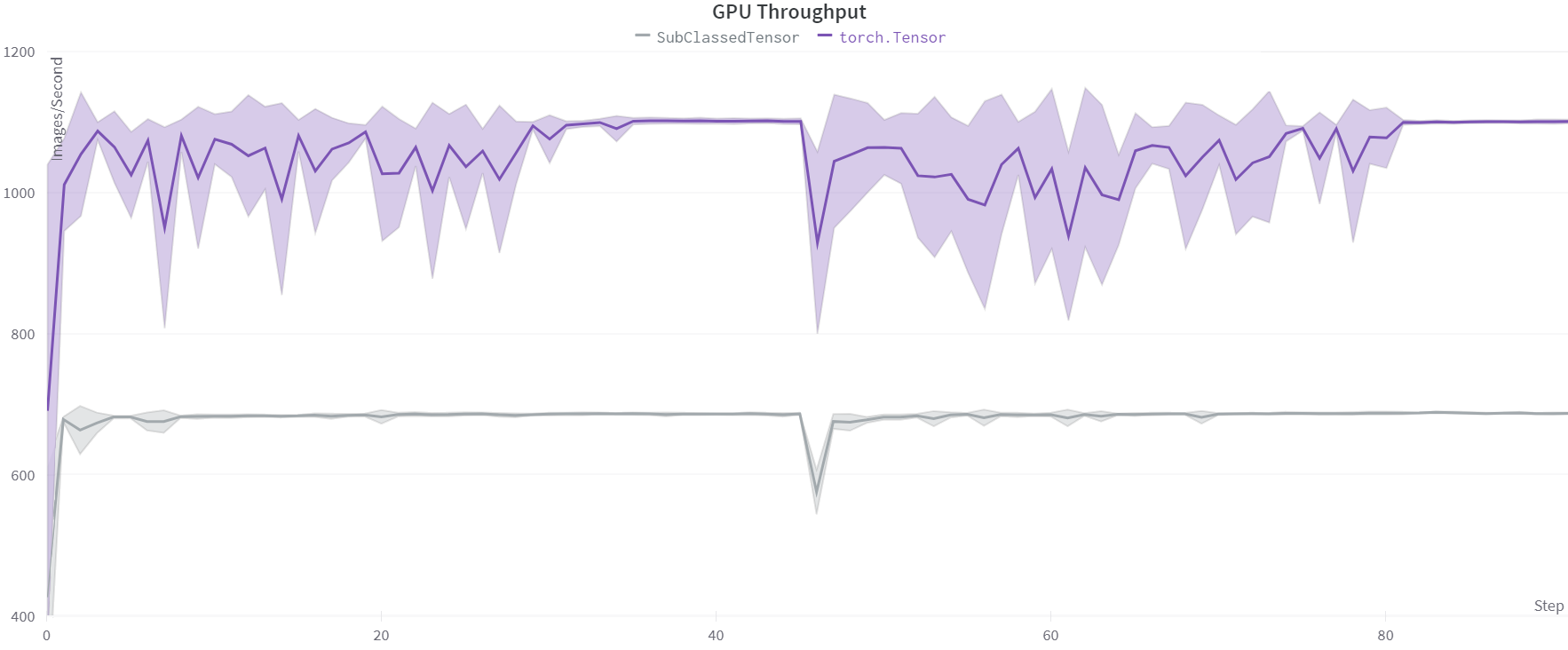
This training decrease persists on more complex derived classes, such as fastai’s TensorBase which follows the extending tensors documentation and implements __torch_function__ for compatibility with torch operations.
The PyTorch documentation doesn’t mention any performance issues when subclassing or extending tensors, so this discovery was a surprise.
# Restoring Performance in fastai
Fortunately, resolving this performance bug is a relatively easy fix. Cast any derived tensor back to torch.Tensor and the performance degradation is eliminated.
For fastai, I created the CastToTensor callback to castcast is a fastcore function which uses Tensor.as_subclass under the hood. all tensor instances to torch.Tensor.
def _cast_tensor(x):
if isinstance(x, tuple):
return tuple(_cast_tensor(x_) for x_ in x)
else:
return cast(x, Tensor) if isinstance(x, Tensor) else x
class CastToTensor(Callback):
"Cast Subclassed Tensors to `Tensor`"
order=9 # Right before MixedPrecision
def before_batch(self):
self.learn.xb = _cast_tensor(self.learn.xb)
self.learn.yb = _cast_tensor(self.learn.yb)
It occurs right before the MixedPrecision callback, so any callbacks which use type dispatch or tensor typesMy CutMixAugment callback uses type dispatch since it defers batch transforms to the callback so they can randomly be applied or not applied. still have access to the information, presuming they run before CastToTensor.
The fix only applies to fastai default model inputs, that is tensors or tuples of tensors. If your input is different, you will need to perform the cast yourself. Import cast from fastcore.dispatch or use Tensor.as_subclass and cast any subclassed tensors to Tensor before passing them to a PyTorch model for a forward pass.
CastToTensor will be added to the fastai Learner by default in the upcoming 2.7.0 release. If you want the fix now or are stuck using an older version of fastai 2, you can copy CastToTensor from the source code or import my backported version from fastxtend.
# Lessons Learned
Framework developers should benchmark their framework against other PyTorch frameworks and vanilla PyTorch itselfBenchmarking against PyTorch XLA, TensorFlow, and Jax would be even better, but that would be more of an apples-to-oranges comparison.. This benchmark shouldn’t be limited to just training speed, but also contain model performance metrics to detect if a recent change may have unintentionally affected the training process.
Neural networks want to learn. Modern PyTorch frameworks have good enough default settings that models often will train on correctly formatted data. Unnoticed introductions of suboptimal settings can still lead to a model that at first glance appears to be learning the training set and generalizing against a validation set.
These benchmarks should run regularly as part of the development cycle to catch any changes which influence performance, both training speed and metrics.
# Why Extend Tensors?
An inevitable question is why does fastai subclass tensors in the first place?
Subclassing tensors can be quite useful. There are three main features fastai’s subclassed tensors add:
- Preserving metadata
- Built in display methods
- Apply actions based on tensor types
Fastai’s subclassed tensors can store and restore metadataPyTorch uses a metadata preserving tensor as their documentation example of a useful tensor subclass. after tensor operationsMy fastxtend audio module makes use of this feature for automatically extracting required metadata from audio tensors for transform operations and saving the spectrogram and mel spectrogram transform settings needed for proper displaying.. This allows users and fastai extensions to focus on their code and not recording and passing metadata.
Fastai tensors also contain methods for displaying themselves, and the library is designed to use this framework for displaying individual and/or batch unaugment inputs, augmented inputs, outputs, and predictions. Extending this functionality to display a new data type often only requires writing a custom single item plotting methodA complicated type might require a little more customization than just a new show method to work. But usually less then writing it all from scratch., as fastai’s display methods are tensor type agnostic.
Assigning different inputs to different tensor types allows for easy modification of inputs in a safe manner. For example, when training and augmenting a segmentation task, fastai augmentations use the tensor type information to rotate both the image and mask, but only apply lighting changes to the input image. Inheriting from TensorMaskMy cloud segmentation project used inheritance from TensorImage and TensorMask for augmentation and a custom show method for GeoTIFF images. to create a new but slightly different segmentation task means the new tensor subclass acquires all the augmentation protections for free.
An example of using all three of these features in combination from fastxtend’s audio module is shown in Figure 2.
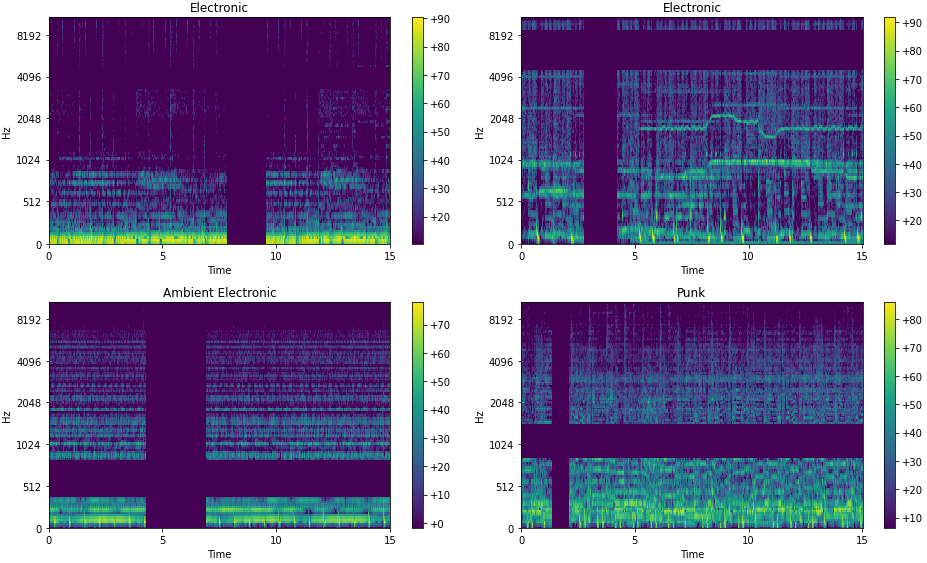
TensorMelSpec using fastai’s show_batch.TensorMelSpec stores the metadata passed to the MelSpectrogram transform which created it. This metadata is used in TensorMelSpec augmentations which use typesTechnically it uses type dispatch. to only apply to TensorMelSpec tensors and the metadata automatically populates transform arguments. Then fastai’s show_batch calls the TensorMelSpec.show method, which uses the metadata and librosa for plotting, generating the sample batch shown above.
# Anatomy of a Performance Bug Hunt
The discovery of a performance bug, experimental confirmation it was due to tensor subclassing, creation of a workaround for fastai, and reporting the bug as a PyTorch GitHub issue took a little under a weekIncluding working on other projects..
The journey started when I messaged Thomas about training in channels last format. I could not figure out why all my attempts at using it resulted in a lack of increased training speed. Mixed precision training appearedMixed precision trained faster then full precision, but it too is affected by the performance bug. to work fine, so I assumed might be an issue with my channels last implementation.
That weekend, Thomas launched a bunch of fastai training runs across different PyTorch image models and torchvision’s ResNet50. He found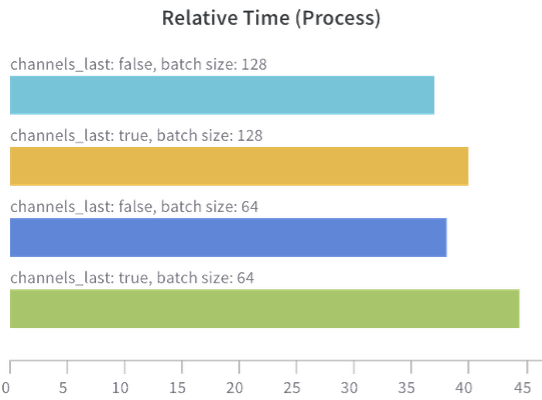
We reviewed the results early in the week. Thomas then tested a pure PyTorch training loop and saw the expected speedup from channels last, but not with fastai.
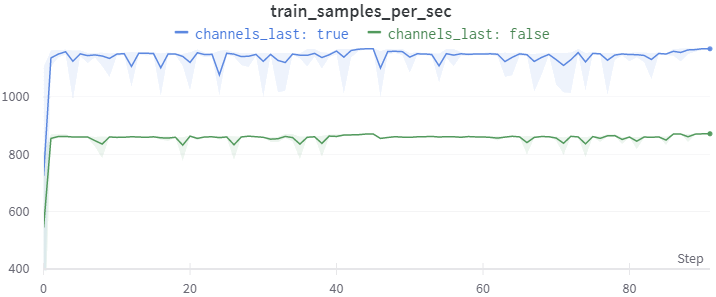
Simultaneously, I tested fastai training with as many of the fastai bits turned off: torch.Tensor inputs instead of TensorImage, a PyTorch optimizer instead of fastai optimizerFastai has its own optimizer implementations to handle discriminative learning rates in different slices of a model., and PyTorch loss function instead of fastai loss functionFastai loss functions cast outputs to TensorBase so there’s no type mismatch when calculating losses., and also saw the expected channels last speed up.
I then determined the slowdown only occurred if a fastai TensorImage or TensorBase was passed to the model and not a torch.Tensor. I also verified the slowdown occurred in PyTorch both 1.11 and 1.10.
Google Colab Tesla T4 Training Results
| PyTorch | Mode | Input | Loss | Optimizer | Epoch | Batch | Forward | Backward | Optimizer Step |
|---|---|---|---|---|---|---|---|---|---|
| 1.11 | Mixed Precision | TensorImage | fastai | fastai | 66.26s | 443.2ms | 61.11ms | 73.15ms | 280.0ms |
| Channels Last | TensorImage | fastai | fastai | 74.08s | 498.0ms | 52.80ms | 53.55ms | 365.1ms | |
| Tensor | torch | torch | 57.79s | 368.2ms | 61.65ms | 56.72ms | 172.8ms | ||
| Tensor | torch | fastai | 57.12s | 379.6ms | 48.32ms | 56.09ms | 182.0ms | ||
| Tensor | fastai | fastai | 56.61s | 375.5ms | 49.67ms | 57.99ms | 177.2ms | ||
| TensorBase | fastai | fastai | 74.25s | 498.3ms | 53.14ms | 56.09ms | 362.4ms | ||
| 1.10 | Mixed Precision | TensorImage | fastai | fastai | 72.51s | 483.8ms | 58.76ms | 58.61ms | 302.8ms |
| Channels Last | TensorImage | fastai | fastai | 76.77s | 514.0ms | 56.88ms | 49.06ms | 377.4ms |
Reproducible code and results here. All timings are the average duration per action. Models trained on Imagenette using a ResNet50 with a warmup epoch prior to benchmarking. Forward and Backward passes average duration on the Tesla T4 appear to be more random than on other GPUs.
But we had not nailed down why. TensorBase appeared to be coded per the PyTorch documentation. The test callbacks I wrote for my channels last callback confirmed the TensorImage input to and output from a single Conv2d model were in channels last format.
Feeling a bit stuck, we presented our results to the fastai development channel. At this point we thought TensorBase was slowing down channels last format training, but mixed precision training was unaffected.
Tanishq Abraham suggested trying a passthrough torch.Tensor subclass, and I confirmed that SubClassedTensorThis is the same SubClassedTensor defined in Subclassed Tensors Reduce Throughput. slowed down channels last format. Finding a performance decrease by ~370-400 images/second on a 3080 Ti, or up to forty percent.
class SubClassedTensor(torch.Tensor):
pass
Thomas tested SubClassedTensor with mixed precision and without channels last, and we were surprisedSuprised because this means fastai has had a unnoticed performance decrease for an undetermined amount of time due to this PyTorch bug. to find that it showed decreased performance too. Thomas reported a decrease of ~200 images/second on a V100 and I measured ~150 images/second decrease on a 3080 Ti.
Once we doublechecked our code and were confident in our results, I created the fastai workaround and a GitHub issue in the PyTorch repo.
The mystery of slower channels last training with fastai was solved.
# Appendix: Performance Testing Code
Our PyTorch training loop, simplified for presentation, can be seen below. Full code is available here.
for step, (images, labels) in enumerate(tqdm(train_dl, leave=False)):
if subclass:
images = images.as_subclass(SubClassedTensor)
images, labels = images.to(device), labels.to(device)
images = images.contiguous(memory_format=torch.channels_last)
with autocast():
outputs = model(images)
train_loss = loss_func(outputs, labels)
train_loss.backward()
optimizer.step()
optimizer.zero_grad()