FlashAttention is a hardware optimized, IO-aware implementation of Attention. FlashAttentionTri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In Advances in Neural Information Processing Systems. builds on Memory Efficient AttentionMarkus N. Rabe and Charles Staats. 2021. Self-attention Does Not Need O(n^2) Memory. arXiv:2112.05682. and Nvidia’s Apex Attention implementations and yields a significant computation speed increase and memory usage decrease over a standard PyTorch implementation.
FlashAttention-2Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning. (2023). builds on FlashAttention, yielding significant speedups on server-class GPUs. But how does it compare when training on consumer level hardware? Unlike the PyTorch implementation of FlashAttention, FlashAttention-2 currently cannot compile into a single Cuda Graph via PyTorch 2.0’s Compile. Does this matter, and if so at what model sizes and sequence lengths?
In this post I attempt to answer these questions by benchmarking FlashAttention and FlashAttention-2 on a consumer GPU.
# FlashAttention
FlashAttention tiles inputs into small blocks which fit on the GPU die’s SRAM. Instead of computing Attention all at onceWhich creates a large Attention matrix, requiring many slow memory reads and writes., FlashAttention computes Attention entirely for each block before moving to the next block, avoiding expensive memory operations for intermediate results. These individual Attention calculations are then parallelized across the GPU’s thread blocks.
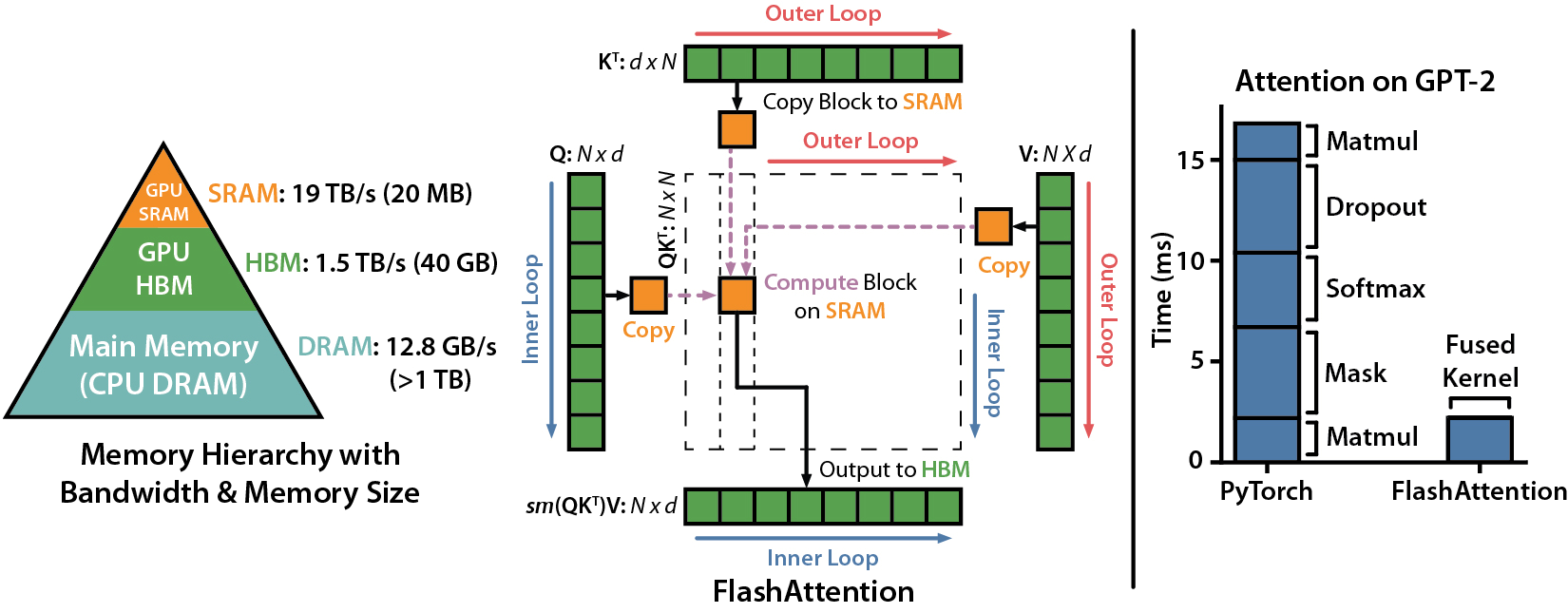
FlashAttention also limits the number of statistics and intermediate results stored for the backward pass, and instead recomputes them on the fly. In addition to being more memory efficient, this recomputation is faster than reading intermediate results from memory.
Combining tiling and recomputation into one Cuda kernel gives FlashAttention up to a speed boost over a standard PyTorch Attention implementation while using up to less memory. This leads to a total modelAll measurements are from the FlashAttention paper while training GPT-2. wallclock reduction of up to over standard PyTorch models.
However, FlashAttention still has some inefficiencies with sub-optimal parallelization, thread partitioning, shared memory access. Dao resolvedDao reports that FlashAttention-2 uses up to 73% of the theoretical max GPU throughput during the forward pass, and up to 63% during the backward pass. these implementation issues with FlashAttention-2 by tweaking the algorithm to use less non-matmul operationsDue to Tensor Cores, matrix multiplications can be up to 16× higher than non-matmul operations., parallelize the forward and backward pass across the sequence length in addition to FlashAttention’s batch and head parallelization, and better computation partitioning between GPU thread block warps to reduce shared memory access. This leads to up to a speed improvement over FlashAttention.
# PyTorch Compile
torch.compile is a new feature introduced in PyTorch 2.0 for training models faster on modern hardwareIn recent GPU generations, compute improvements have been lapping memory speed improvements, which means PyTorch’s eager mode isn’t as compute efficient as it has been on older hardware.. By default, PyTorch Compile uses Triton to JIT-compile PyTorch code into fused and optimized Cuda kernels, increasing computational efficiency while reducing memory transfers and overheadFor more details on memory transfer and overhead, check out Horace He’s Making Deep Learning Go Brrrr From First Principles.. PyTorch Compile then turns these operations into Cuda Graphs where possible, reducing the overhead costs and allowing faster training.
When an operation isn’t supported by PyTorch Compile, model execution falls back to standard PyTorch eager mode. This can significantly slow down the execution of a model, even for a few fallbacks to eager mode.
At the time of writing, FlashAttention-2 cannot compile into PyTorch Compile graphFlashAttention-2 uses two features incompatible with Compile in PyTorch 2.0.1: autograd.Function and a unregistered custom Cuda call. The former should be fixed in PyTorch 2.1 but the latter requires modification to FlashAttention., a graph break with PyTorch Compile. But PyTorch’s implementation of FlashAttention, scaled_dot_product_attention is fully compatible with PyTorch Compile, and more importantly fullgraph=True option, which compiles the model into a single Cuda GraphAlthough you do need to ignore the PyTorch documentation and not use a context manager. See the appendix for details..
This raises an interesting question. Which is faster, the slower FlashAttention compiled into a single Cuda Graph, or the faster FlashAttention-2 with graph breaks in each Attention layer?
# Testing Setup
Code to replicate this post can be found here. The results in this post used incorrect transposing for FlashAttention-2’s output (fixed in the replication code). This should have little to no effect in the benchmarking results.I elected to follow Dao et al in benchmarking FlashAttention using both GPT-2Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training. (2018). Retrieved from https://openai.com/research/language-unsupervised small and medium models. I additionally test using GPT-2 large. The implementation is taken from commented-transformers, modified to support both PyTorch’s FlashAttention and FlashAtttention-2. I made three changes to the GPT-2 model architecture. I use a vocabulary size of 16,384, disable the bias terms in all linear layersThese settings were selected both to enable GPT-2 medium to more easily fit in 12GB and for the increase in training speed over the standard GPT-2 vocab size., and turn off dropout.
All models were benchmarked in Float16 Mixed Precision with Mosaic’s Composer using the PyTorch ForEach implementation of AdamWIlya Loshchilov and Frank Hutter. 2019. Decoupled Weight Decay Regularization. arXiv:1711.05101.. For GPT-2 large, I replaced the PyTorch optimizer with 8-bit AdamWTim Dettmers, Mike Lewis, Sam Shleifer, and Luke Zettlemoyer. 2022. 8-bit Optimizers via Block-wise Quantization. arXiv:2110.02861. to allow larger sequence lengths to fit in memory. To prevent PyTorch Compile time from affecting the results, model throughput was averaged over the last 25 batches of a 125 batch run using Composer’s SpeedMonitor callback. With the exception of GPT-2 large, all batch sizes were decreased by eight at a time until reaching a batch size of eight.
All benchmarks are ran on the same Nvidia RTX 3080 Ti, an Ampere consumer GPU with 12GB of RAM. To mitigate any effect of the hardware lottery, I limit the boost clock to the stock setting of 1665 MHz and power to 300 Watts. Models were ran using PyTorch 2.0.1 with Cuda 11.8 and FlashAttention 2.0.4 compiled against both Ampere SM80 and SM86.
# Results
A priori, I’d expect as the context length increases and the batch sizes get smaller, the ability of FlashAttention-2 to parallelize across sequence length will trump the speed decrease from Cuda Graph breaks. The question of which implementation achieves faster training speed will be at the smaller sequence lengths.
Table 2 and Figure 3 show the results of benchmarking with PyTorch Compile. The difference columns are the primary metric of interest, as it shows the relative performance between FlashAttention-2 compiled with graph breaks and PyTorch’s FlashAttention compiled into a single Cuda Graph.
FlashAttention & PyTorch Compile
| PyTorch | FlashAttention | FlashAttention-2 | Difference | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| GPT | Context Length | Batch Size | Tokens/Sec | Batch Size | Tokens/Sec | Speedup | Tokens/Sec | Speedup | Tokens/Sec | Percent |
| Small | 265 | 52 | 63,820 | 64 | 72,785 | 14.0% | 71,628 | 12.2% | -1,157 | -1.6% |
| 512 | 16 | 52,199 | 32 | 68,044 | 30.4% | 68,051 | 30.4% | 7 | 0.0% | |
| 768 | 8 | 46,109 | 24 | 66,790 | 44.9% | 67,465 | 46.3% | 675 | 1.0% | |
| 1024 | 6 | 42,936 | 16 | 65,065 | 51.5% | 65,523 | 52.6% | 458 | 0.7% | |
| 1536 | 3 | 35,495 | 8 | 59,840 | 68.6% | 60,351 | 70.0% | 511 | 0.8% | |
| 2048 | 1 | 24,602 | 8 | 60,257 | 145% | 61,153 | 149% | 896 | 1.5% | |
| 3072 | 1 | 22,804 | 5 | 55,342 | 143% | 56,480 | 148% | 1,138 | 2.0% | |
| 4096 | 4 | 37,697 | 53,791 | 16,094 | 29.9% | |||||
| Medium | 256 | 16 | 17,750 | 24 | 20,914 | 18% | 20,601 | 16.1% | -313 | -1.5% |
| 512 | 6 | 15,302 | 8 | 18,310 | 19.7% | 18,316 | 19.7% | 6 | 0.0% | |
| 768 | 3 | 13,010 | 8 | 19,984 | 53.6% | 19,959 | 53.4% | -25 | -0.1% | |
| 1024 | 1 | 8,585 | 6 | 19,725 | 129.8% | 19,719 | 129.7% | -6 | 0.0% | |
| 1536 | 1 | 9,688 | 4 | 19,064 | 96.8% | 19,124 | 97.4% | 60 | 0.3% | |
| 2048 | 3 | 15,807 | 18,557 | 2,750 | 14.8% | |||||
| 3072 | 2 | 12,089 | 17,546 | 5,457 | 31.1% | |||||
| 4096 | 1 | 6,886 | 14,633 | 7,747 | 52.9% | |||||
| Large | 256 | 10 | 8,670 | 8,960 | 290 | 3.2% | ||||
| 512 | 5 | 8,451 | 8,861 | 410 | 4.6% | |||||
| 768 | 3 | 8,089 | 8,448 | 359 | 4.2% | |||||
| 1024 | 2 | 7,061 | 7,904 | 843 | 10.7% | |||||
| 1536 | 1 | 5,361 | 7,034 | 1,673 | 23.8% | |||||
| 2048 | 1 | 5,103 | 7,308 | 2,205 | 30.2% | |||||
Difference is the performance change between FlashAttention-2 & FlashAttention. Speedup is the increase relative to the standard PyTorch implementation. Blank sections are where standard PyTorch ran out of memory. Both standard PyTorch & FlashAttention were compiled as a single Cuda Graph while FlashAttention-2 was compiled with graph breaks.
All three GPT-2 model sizes show the anticipated trends. As the sequence length increases and the batch size decreases, FlashAttention-2 increasingly outperforms FlashAttention, despite the former suffering from graph break slowdowns.
The interesting results are for the shorter sequence lengths and larger batch sizes. For GPT-2 Small and Medium, PyTorch’s FlashAttention has roughly the same training speed until a context length of 2048 tokens. At a sequence length of 256, FlashAttention-2 is ~1.5% slower than FlashAttention for both GPT-2 Small and MediumJust above an eyeballing of training variance.. From context lengths of 512-1536 the performance difference is near indistinguishable from training variance.

Unlike GPT-2 Small and Medium, FlashAttention-2 has a small but consistent performance advantage on GPT-2 Large for all 256-768 sequence lengths. This appears to be FlashAttention-2’s better parallelization and warp handling leading to increased performance on larger hidden sizes.

GPT-2 Medium: FlashAttention & PyTorch Eager Mode
| FlashAttention | FlashAttention-2 | Difference | ||||
|---|---|---|---|---|---|---|
| Context Length | Batch Size | Tokens/Sec | Batch Size | Tokens/Sec | Tokens/Sec | Percent |
| 256 | 24 | 19,993 | 24 | 20,993 | 1,001 | 4.8% |
| 512 | 8 | 17,449 | 8 | 18,195 | 746 | 4.1% |
| 1024 | 6 | 18,746 | 6 | 19,503 | 758 | 3.9% |
| 2048 | 3 | 15,202 | 2 | 17,107 | 1,905 | 11% |
| 3072 | 2 | 11,730 | 1 | 15,307 | 3,577 | 23% |
| 4096 | 1 | 6,821 | 1 | 15,038 | 8,216 | 55% |
Difference is the performance change between FlashAttention-2 & FlashAttention. Batch sizes do not match as FlashAttention-2 used a bit more memory then FlashAttention.
These results show that even with larger batch sizes and smaller sequence lengths, where FlashAttention is at less of a disadvantage, FlashAttention-2 still has a small but consistent performance of advantage 4 to 6 percent. This suggests that the rest of the model is not completely overpowering the benefits of FlashAttention-2 at larger batch sizes. Rather FlashAttention-2’s inability to compile to a full Cuda Graph is leaving 4 to 6 percent of additional performance on the table.
One additional improvement of FlashAttention-2 over FlashAttention is the former natively supports both Multi Query AttentionNoam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need. arXiv:1911.02150. and Grouped Query AttentionJoshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. arXiv:2305.13245. without creating additional copies of keys or values. While I did not test this improvment, I suspect that FlashAttention-2 will tie or outperform FlashAttention due to the reduced memory and copying overhead when using MQA and GQA.
# Conclusion
FlashAttention-2 is a clear an improvement over FlashAttention, even on consumer GPUs. However, due to FlashAttention-2 currently being unable to compile into a single Cuda Graph, there are still cases where PyTorch’s FlashAttention can match or outperform FlashAtttention-2. Namely, smaller models when context lengths are short and batch sizes relatively large. For GPT-2 Small and Medium, this advantage ends at a context length of 2048.
If the model can be compile into a single Cuda Graph via PyTorch Compile, then it’s worth looking into which version of FlashAttention provides greater performance. If the model cannot, or it uses MQA or GQA, then one should probably use FlashAttention-2 for maximum throughput.
At least until FlashAttention-2 is integrated into PyTorch.
# Appendix
The PyTorch documentation for scaled_dot_product_attention states it’s preferred to use a context manager when setting scaled_dot_product_attention modes. However, as of PyTorch 2.0.1, context managers break Cuda Graphs. To compile PyTorch’s FlashAttention into a single Cuda Graph one needs ignore the documenation and call enable_flash_sdp outside of a context manager, as shown in this simple CausalAttention implementation below.
class CausalAttention(nn.Module):
def __init__(self, hidden_size:int, num_heads:int, context_size:int,
bias:bool=True, flash:bool=True):
super().__init__()
assert hidden_size % num_heads == 0
self.nh = num_heads
self.Wqkv = nn.Linear(hidden_size, hidden_size * 3, bias=bias)
self.Wo = nn.Linear(hidden_size, hidden_size, bias=bias)
self.flash = flash
if flash and not torch.backends.cuda.flash_sdp_enabled():
torch.backends.cuda.enable_flash_sdp(True)
def forward(self, x: Tensor):
B, S, C = x.shape
x = self.Wqkv(x).reshape(B, S, 3, self.nh, C//self.nh)
q, k, v = x.transpose(3, 1).unbind(dim=2)
if self.flash:
x = F.scaled_dot_product_attention(q, k, v, is_causal=True)
else:
# alternative attention implementation
x = x.transpose(1, 2).reshape(B, S, C)
return self.Wo(x)