While working through Unit 3 of the Hugging Face Reinforcement Learning course, I was feeling impatient by how long it took for the suggested DQN configuration to finish trainingA million steps took over an hour on my machine while barely using any system resources..
The up-to-date source code for this post is available here. In-line links are to the code at the time this post was published.I decided to investigate the lethargic performance and succeeded in increasing the training speed of Atari DQN agents by a factor of three to fourteen using EnvPool and a custom PyTorch GPU replay memory buffer.
# CleanRL as the Base
In Unit 3, Hugging Face suggests using Stable Baselines3 (SB3)Specifically, Hugging Face suggests using SB3’s RL Baselines3 Zoo’s Atari DQN training script. to train Atari DQN agents. From my brief look into the codebase, SB3 looks well designed and implemented, but doesn’t appear to be the most hackable or flexible library. Or at least it doesn’t for a new user like me. So I decided to switch reinforcement learning libraries.
Like Hugging Face’s Transformers library, CleanRL is a single fileCleanRL’s single file implementations are nice because it’s quite easy to see how the model works in practice relative to the equation form. implementation of reinforcement learning models. Almost everything one needs to launch and train a model on a gym environment is in 231 lines of code. Plus a few imported features.
# The Need for Speed
With a more “hackable” code setup, it was time to turn to the two major training speed bottlenecks: The “slow” CPU gym environmentsIn prior units, I increased the number of environments using SB3’s DummyVecEnv and SubprocVecEnv wrappers and while they worked, they still felt slow and used too much RAM. However, due to my lack of familiarity with SB3, this might be due to user error. and the NumPy-based replay buffers.
# EnvPool
According to the documentation, EnvPool is a fast C++-based, multithreaded, gym-compatible environment engine which supports synchronous and asynchronous execution, and single- and multi-player environments. It’s supposed to provide ~2X speedup compared to a single gym environment and is supposed to have ~3X to ~20X the throughput of a Python subprocess-based vector environment on low coreWhere low-core is defined as twelve CPU cores. A bit more than my current machine’s four. My CPU is old. and high core machines, respectively.
This sounded quite promising and easier to use then some of the alternative fast environments, like CuLE and gymnax, both which have their downsidesCuLE is hard or impossible to compile for Ampere GPUs and gymnax only supports MinAtar, not full Atari games. However, CuLE should be easier compile for Turing or Pascal GPUs..
EnvPool is mostly a drop-in replacement for a gym or SB3 gym environment. It natively implements gym.Wrappers like episodic lives, observation resizing, gray scaling, and frame stacking. The only three wrappers I added to it were a RecordEpisodeStatistics wrapper from CleanRL to record the game stats, a VecAdapter from EnvPool’s SB3 integration examples, and VecMonitor from SB3 for model evaluation.
# training envpool setup
envs = envpool.make(*args)
envs.num_envs = args.num_envs
envs.single_action_space = envs.action_space
envs.single_observation_space = envs.observation_space
envs = RecordEpisodeStatistics(envs)
# evaluation envpool setup
eval_env = envpool.make(*args)
eval_env.spec.id = args.env_id
eval_env = VecAdapter(eval_env)
eval_env = VecMonitor(eval_env)
The above code excerpted from lines 185 to 203 illustrates setting up EnvPoolargs includes things like the gym env_id, num_envs, and seeds. See code for details. for Atari gyms, where setting variables like envs.single_action_space is for convenience and compatibility.
The only downside to EnvPool is it runs on the CPU, which means I still have to do a CPU to GPU transfer. But I can decrease the amount spent on that task using a GPU replay memory buffer.
# PyTorch GPU Replay Memory Buffer
With a hopefully faster environment manager in place, it was time to look at the next potential source of sluggishness: the NumPy replay memory buffer.
While NumPy is pretty fastZach Mueller sped up fastai tabular up to ~8X by replacing the Pandas backend with a NumPy backend., skipping the transfer time from CPU memory to GPU memory while training is even fasterAnd then I riffed on that idea to speed up fastai tabular up to ~20X by replacing the Pandas backend with a PyTorch GPU backend.. Especially since most reinforcement learning environments that I’ve seen so far don’t use a dataloader to preprocess and/or asynchronously place the replays on the GPU just in time.
Creating the PyTorch replay buffer was simple. I took the SB3 ReplayBuffer and replaced everything NumPy with it’s PyTorch equivalent and cut anything not needed for Atari gyms. My TorchAtariReplayBuffer can be set to storedIf your GPU has at least 10-12GB of memory, I’d recommend setting the device to the GPU for Atari envs if using the standard 80K-120K replay size. on any PyTorch compatible device.
With the exception of the observations frames, SB3’s ReplayBuffer hardcodes everything to be stored as float32To be fair, the frames are the bulk of the storage cost.. To save a little more memory, my TorchAtariReplayBuffer stores data as each observation’s PyTorch dtypeCurrently this is hardcoded to Atari games, but could be improved to work with any env..
With the PyTorch GPU replay memory buffer in place, the CPU to GPU transfer process is now:
- Take random actions on the CPU
- Play an observation using the DQN model on the GPU (if applicable)
- Send the predicted actions to CPU
- Combine played actions with random actions per epsilon greedy
- Take a step using EnvPool on CPU
- Transfer next observation and results from playing current observation to GPU
The code for these six steps, excerpted from lines 254-288, looks like thisThe observant reader will notice that dones isn’t transferred to the GPU until the last line. That’s because it’s used to save some stats on the CPU first in cut out code.:
# take random actions, play observations, combine per epsilon greedy
rand_actions = nprng.integers(0, envs.single_action_space.n, envs.num_envs)
if epsilon < 1:
with torch.no_grad():
logits = q_network(obs)
actions = torch.argmax(logits, dim=1)
actions = actions.cpu().numpy()
idxs = np.where(nprng.random(args.num_envs) < epsilon)[0]
if len(idxs) > 0:
actions[idxs] = rand_actions[idxs]
else:
actions = rand_actions
# play out the next step using envpool
next_obs, rewards, dones, infos = envs.step(actions)
# transfer from CPU to GPU
next_obs = torch.from_numpy(next_obs).to(device)
actions = torch.from_numpy(actions).to(device)
rewards = torch.from_numpy(rewards).to(device)
dones = torch.from_numpy(dones)
real_next_obs = next_obs.clone()
# save observations to GPU replay memory buffer
rb.add(obs, real_next_obs, actions, rewards, dones.to(device), infos)
With these transfers set up, it’s now possible to train the DQN model from GPU memory.
# Testing Results
All training runs were conducted for 500,000 steps on Space Invaders V4 with one round of evaluation play at the end included in the total training time.
Figure 1 shows the timed results of training 500,000 steps of Space Invaders using the SB3 defaults via RLZoo3 of one environment and a batch size of thirty-two.
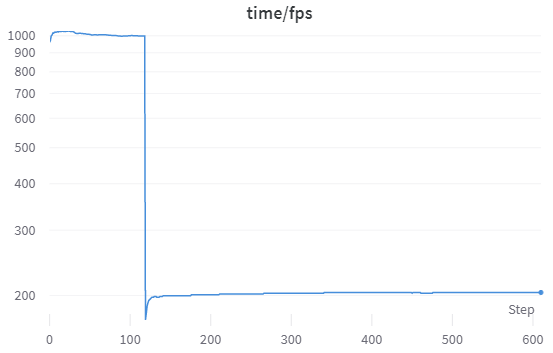
Total training time for 500,000 stepsSB3 doesn’t record the actual number of steps in the chart, but rather something else. was 39 minutes 14 seconds with a play speed of ~1,000 fps and a training speed of ~204 fps.
Figure 2 shows two tests with EnvPool and GPU replay memory. A SB3 defaults matching one environment and with 128 environments. Both with a batch size of thirty-two.
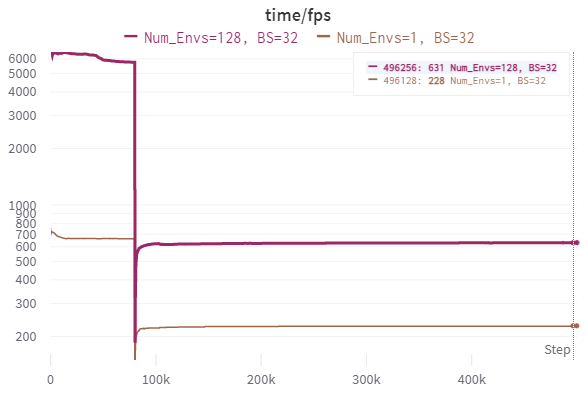
The single environment trained for 500,000 stepsMy implementation records the correct number of steps. in 33 minutes and 27 seconds, and the 128 environments trained in 12 minutes and 8 secondsThis result gives lower bound of the eponymous claim of three times faster training..
Unlike documentation’s claims, EnvPool was slower during initial random play than SB3’s DummyVec environment at ~664 fps. However, switching to 128 environments shows that running one environment is wasting EnvPool’s potential. The slowest pre-training speed is ~5755 fps.
500,000 Steps With a Batch Size of 32
| Number of Envs | Approx Play FPS | Approx Train FPS | Total Time (min:sec) | |
|---|---|---|---|---|
| SB3 | 1 | 1,000 | 204 | 39:14 |
| EnvPool | 1 | 664 | 227 | 33:27 |
| EnvPool | 128 | 5755 | 630 | 12:08 |
EnvPool includes GPU replay memory. All results are from a single run and includes one round of evaluation after 500,000 steps.
The PyTorch GPU replay memory implementation is responsible for an increase of ~23 fps during model training, a ~11% improvement over using NumPy replay memory. This improvement is due to eliminating the time cost of transferring a batch of 32 observations from CPU to GPU memory.
Using GPU replay memory really starts to shine when switching to the 128-environment run. EnvPool takes 128 steps in parallel and then the model trains on 32 batches of 32 observationsThis matches the train frequency of four in default settings. in a row, which allows a training speed increase to ~630 fps.
# We Can Go Faster
A batch size of 32 is small and the DQN model is in no danger of maxing out available GPU compute, so the next step is to increase the batch size. Figure 3 shows the results of training for 500,000 frames at a batch size of 128, 512, and 2048.
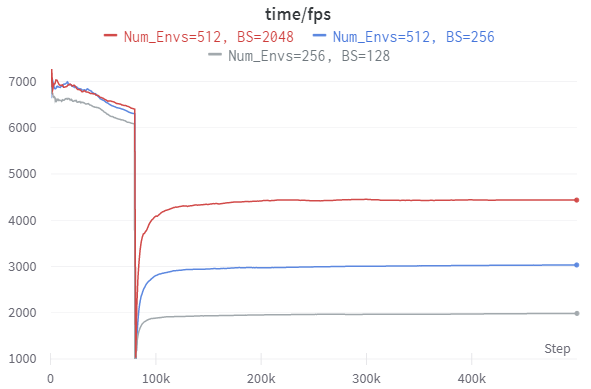
This results in training times of 4:51All times reported in minutes:seconds., 3:34, and 2:29This result gives upper bound of the eponymous claim of fourteen times faster training. at a speed of ~1980 fps, ~3025 fps, and ~4440 fps, respectively.
500,000 EnvPool Steps With Large Batch Size
| Number of Envs | Batch Size | Approx Play FPS | Approx Train FPS | Total Time (min:sec) |
|---|---|---|---|---|
| 256 | 128 | 6099 | 1980 | 4:51 |
| 512 | 256 | 6317 | 3025 | 3:34 |
| 512 | 2048 | 6427 | 4440 | 2:29 |
All results use PyTorch GPU replay memory and are from a single run and includes one round of evaluation after 500,000 steps.
For the larger batch sizes, I increased the number of environments to 256, 512, and 512 for the batch sizes of 128, 256, and 2048. This is pushing the limits of my old four core CPU. Still, it managed a respectable ~6099 fps and 6317-6427 fps for 256 and 512 environments, respectively.
It might be possible to train faster with an even larger batch size, but the increase from 256 to 2048 only shaved a minute off training time while looking significantly different from the smaller batch sizes in training behavior.
# More Charts
Figure 4 shows my hardware usage statistics as automatically tracked by Weights and Biases. The delay for the one environment run is due to the slow random playing of the game before the GPU is fully engaged.
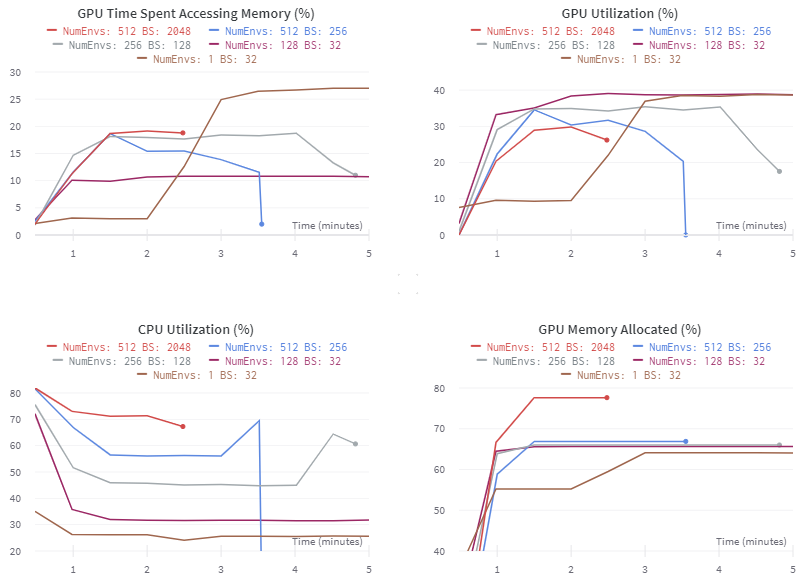
The GPU still isn’t close to maxed out even when training at a batch size of 2048. And there’s even room in memory to use a larger CNN model or a larger replay buffer, if desired.
# Conclusion
Half a million frames in under three minutes is pretty greatI stopped increasing the batch size at 2048 since the training speed appears to be approaching diminishing returns., and if you want something closer to the default hyperparameters a batch size of 128 completing in under five minutes is also quite nice.
For a batch size of 2048, the default hyperparameters from CleanRL and SB3 are not anywhere near optimal. But you should be able to perform a hyperparameter sweep across 140 million steps in the same time or less then it would take to train one model using the SB3 defaults for 10 million steps. An acceptable tradeoff in my book.
# P.S.
As far as I am aware, the only easyIt might be possible to train faster by having EnvPool run on one subprocess and the training loop on another. But this doesn’t qualify as easy. way to train Atari DQN agents significantly faster on the same hardware would be to cut out the CPU to GPU transfers completely. Which would be possible if Nvidia updated CuLE to support modern GPUs or added Atari to Issac Gym. Or if gymnax added support for full Atari games.